 |
|
|
UNIX - это ядро операционной системы разделения времени, то есть программа, которая распоряжается ресурсами вычислительной машины и предоставляет их пользователям. Она дает пользователям возможность запускать свои программы, управляет периферийными устройствами и обеспечивает работу файловой системы. UNIX является многозадачной, многопользовательской ОС.
Работу ОС UNIX можно представить в виде функционирования множества взаимосвязанных процессов. При загрузке системы сначала запускается ядро (процесс 0), которое в свою очередь запускает командный интерпретатор shell (процесс 1).
Взаимодействие пользователя с системой UNIX происходит в интерактивном режиме посредством командного языка. Оболочка операционной системы - shell - интерпретирует вводимые команды, запускает соответствующие программы (процессы), формирует и выводит ответные сообщения.
Важной составной частью UNIX является файловая система. Она имеет иерархическую структуру, образующую дерево каталогов и файлов. Корневой каталог обозначается символом "/", путь по дереву каталогов состоит из имен каталогов, разделенных символом "/", например:
/usr/include/sys
В каждый момент времени с любым пользователем связан текущий каталог, то есть местоположение пользователя в иерархической файловой системе.
Каждый файл ОС UNIX может быть однозначно определен некоторой структурой данных, называемой описателем файла (дескриптором). Он содержит всю информацию о файле: тип файла, режим доступа, идентификатор владельца, размер, адрес файла, даты последнего доступа и последней модификации, дату создания и пр.
Обращение к файлу происходит по имени. Локальное имя файла представляет собой набор символов, в версии System V имеющий длину от 1 до 14. В качестве символов следует использовать цифры, буквы латинского алфавита и символ ‘_’. Локальное имя файла хранится в соответствующем каталоге. Путь к файлу от корневого каталога называется полным именем файла. Если обращение к файлу начинается с символа "/", то считается, что указано полное имя файла и его поиск начинается с корневого каталога, в любом другом случае поиск файла начинается с текущего каталога.
У любого файла может быть несколько имен. Фактически, имя файла является ссылкой на файл, специфицированный номером описателя.
1.1.2. Регистрация в системе
Работа пользователя в системе начинается с того, что активизируется сервер терминального доступа getty, который запускает программу login, запрашивающую у пользователя имя и пароль.
Далее происходит проверка аутентичности пользователя в соответствии с той информацией, которая хранится в файле /etc/passwd. В этом файле хранятся записи, содержащие
� � регистрационное имя пользователя;
� � зашифрованный пароль;
� � идентификатор пользователя;
� � идентификатор группы;
� � информация о минимальном сроке действия пароля;
� � общая информация о пользователе
� � начальный каталог пользователя
� � регистрационный shell пользователя
Если пользователь зарегистрирован в системе и ввел правильный пароль, login запускает программу, указанную в /etc/passwd - регистрационный shell пользователя
1.2. РАБОТА С ФАЙЛАМИ
1.2.1. Пользователи системы и владельцы файлов
Пользователь системы - это объект, обладающий определенными правами, определяющими возможность запуска программ на выполнение, а также владение файлами. Единственный пользователь системы, обладающий неограниченными правами - это суперпользователь или администратор системы.
Система идентифицирует пользователей по т.н. идентификатору пользователя (UID - User Identifier). Каждый пользователь является членом одной или нескольких групп - списка пользователей, имеющих сходные задачи. Каждая группа имеет свой уникальный идентификатор группы (GID - Group Identifier) Принадлежность группе определяет совокупность прав, которыми обладают члены данной группы.
Права пользователя UNIX - это прежде всего права на работу с файлами. Файлы имеют двух владельцев - пользователя (user owner) и группу (group owner).
Соответственно атрибуты защиты файлов определяют права пользователя-владельца файла (u), права члена группы-владельца (g) и права всех остальных (o).
1.2.2. Перенаправление потоков и программные каналы
В ОС UNIX существует три стандартных потока: поток ввода, поток вывода и поток стандартного протокола (поток ошибок).
Перенаправление потоков позволяет изменить стандартный ввод/вывод: < - изменение источника стандартного ввода; >, >> - изменение приемника стандартного вывода.
Примеры:
cat > filename - перенаправление вывода программы cat в файл filename (если этот файл существует, то его прежнее содержимое будет утеряно);
cat >> filename - добавить содержимое вывода программы cat к содержимому файла filename;
cat < filename - сформировать стандартный ввод программы cat из содержимого файла filename.
Стандартные потоки - поток ввода, поток вывода и поток ошибок (поток протокола) имеют фиксированную нумерацию - 0, 1 и 2 соответственно. Эти номера (номера дескрипторов потоков) можно использовать в явном виде. Например, запись
prog 1>file
эквивалентна записи
prog >file
Для того, чтобы отличить имя потока от имени файла, перед номером потока ставится символ ‘&’:
prog >file 2>&1
Здесь происходит перенаправление стандартного потока вывода в файл file (>file). А кроме того, сообщения об ошибках также будут перенаправлены в файл file: запись 2>&1 означает перенаправление потока ошибок на стандартный поток вывода, который, в свою очередь, был перенаправлен в файл.
Замечание: анализ команды осуществляется интерпретатором справа налево: сначала происходи слияние потоков (2>&1), а затем перенаправляется стандартный поток вывода (1) в файл file.
В связи с этим бывает полезно использование псевдоустройства /dev/null, удаляющего все введенные в него символы. Это используется тогда, когда необходимо полностью игнорировать (подавить) выходные потоки.
Канал - это программное средство, связывающее процессы ОС UNIX буфером ввода/вывода. Запуск процессов в виде
$ процесс_1 | процесс_2 | ... | процесс_n
означает, что стандартный вывод процесса_1 будет замкнут на стандартный ввод процесса_2, стандартный вывод процесса_2 будет замкнут на стандартный ввод процесса_3 и т.д. При этом сначала создается канал, а потом на выполнение одновременно запускаются все процессы, и общее время их выполнения определяется более медленным процессом.
Пример: ls | wc -l
Те же действия можно организовать так:
ls > buffer
wc -l < buffer
rm -f buffer
Команда ls выводит на экран (стандартный поток вывода) список файлов текущего каталога, а команда wc -l считает количество строк во входном потоке (в файле, а если файл не указан - в стандартном входном потоке). Таким образом, объединение этих двух команд программным каналом позволяет посчитать количество файлов в текущем каталоге.
Итоговая таблица:
|
> file |
Перенаправление стандартного потока вывода в файл file |
|
>> file |
Добавление в файл file данных из стандартного потока вывода |
|
< file |
Получение стандартного потока ввода из файла file |
|
p1 | p2 |
Передача стандартного потока вывода программы p1 в поток ввода программы p2 |
|
n > file |
Переключение потока вывода из файла с дескриптором n в файл file |
|
n >> file |
Добавление записей потока вывода из файла с дескриптором n в файл file |
|
n > &m |
Слияние потоков с дескрипторами n и &m |
1.3. КОМАНДНЫЙ ЯЗЫК СИСТЕМЫ UNIX
Набор имени команды производится с клавиатуры после появления промпта (приглашения), обычно, - $.
Для облегчения работы с системой UNIX имеется возможность использовать шаблоны имен файлов (или метасимволв):
? - один любой символ;
* - произвольное количество любых символов.
Например:
*.c - задает все файлы с расширением "c";
pr???.* - задает файлы, имена которых начинаются с "pr", содержат пять символов и имеют любое расширение.
1.3.1. Справочные команды
date - получение даты и времени.
who - получение списка пользователей, работающих в системе в данный момент.
Пример:
$ who
petr tty4i Mar 11 18:46
ann tty12 Mar 11 16:29
Выводится имя пользователя, номер терминала, дата и время начала работы этого пользователя. Команда who am i выведет информацию о самом пользователе.
man - получение справочной информации:
$ man [имя команды]
Альтернативой команды man в некоторых клонах UNIX является команда use:
use [имя команды]
1.3.2. Команды работы с каталогами
pwd - печать имени текущего каталога. Например:
$ pwd
/usr/work/petr
ls - вывод на экран содержимого каталога:
$ ls [-ключи] [имя каталога]
Если имя каталога не указано, выводится содержимое текущего каталога. Ключи определяют формат выдачи, например:
-l - вывод полной информации о каждом файле;
-a - вывод полного списка файлов, включая "." и "..";
-t - сортировка списка по времени создания;
-C - вывод списка в несколько колонок по алфавиту и т.п.
Пример:
$ ls –l
total 5
drwxrwxrwx 6 petr������� user1�������������������� 496����������������������� Mar 10� 12:01���� tmp
-rw-rw-r--��������1������������ petr������� user1�������������������� 156����������������������� Mar 12� 15:26���� file.c
-rwxrwx--x������ 2������������ root������� root����������������������� 4003��������������������� Apr 01�� 11:44���� pe.out
cd - смена директории (каталога):
$ cd [полное_имя_каталога]
При этом указанный каталог станет текущим. Команда cd без аргументов восстановит в качестве текущего каталога начальный каталог пользователя.
mkdir - создание нового каталога:
$ mkdir [-ключи] имя_нового_каталога
Для создания нового каталога пользователь должен иметь право записи в родительский каталог текущего каталога.
rmdir - удаление директории:
$ rmdir список_каталогов
Система не позволит удалить каталог, если он не пуст или если у пользователя нет прав записи в него. Текущий каталог не должен принадлежать поддереву удаляемых каталогов.
1.3.3. Команды работы с файлами
rm - удаление файлов (ссылок на файл):
$ rm [-ключи] список_файлов
Эта команда удаляет ссылки на файлы (то есть локальные имена файлов), если у пользователя есть право записи в каталог, содержащий эти имена. Если удаляемый файл защищен от записи, команда запрашивает подтверждение на удаление файла.
Ключи:
-i - вводит необходимость подтверждения для каждого удаляемого файла;
-f - отменяет необходимость подтверждения для любого удаляемого файла;
-r - задает режим рекурсивного удаления всех файлов и подкаталогов данного каталога, а затем и самого каталога.
chmod - изменение атрибутов защиты файла:
$ chmod атрибуты список_файлов
Атрибуты файла могут быть заданы разными способами:
1) буквенной кодировкой. Атрибуты защиты обозначаются так:
r - доступ по чтению;
w - доступ по записи;
x - доступ по исполнению.
Категории пользователей задаются следующим образом:
u - атрибуты для владельца файла;
g - атрибуты для группы владельца файла;
o - атрибуты для прочих пользователей;
a - атрибуты для всех категорий пользователей.
Производимая операция кодируется с помощью таких символов:
= - установить значения всех атрибутов для данной категории пользователей;
+ - добавить атрибут для данной категории пользователей;
- - исключить атрибут для данной категории пользователей.
Пример. Разрешить доступ по чтению и записи к файлам с именем mar владельцу и группе-владельцу:
$ chmod ug+rw mar.*
2) в виде восьмеричного числа. Числовые значения атрибутов защиты кодируются трехразрядным восьмеричным числом, где существование соответствующего атрибута соответствует наличию единицы в двоичном эквиваленте восьмеричной цифры этого числа, а отсутствие атрибута - нулю. Например:
символьное представление����������������������� rwx����� r-x������ r--
двоичное представление��������������� 111����� 101����� 100
восьмеричное представление������� 7��������� 5��������� 4
Пример. Установить атрибуты чтения и записи для владельца и группы-владельца и только чтения для остальных пользователей:
$ chmod 0664 gb??.doc
cat - слияние и вывод файлов на стандартное устройство вывода:
$ cat [-ключи] [входной_файл1[входной_файл2...]]
Команда по очереди читает указанные входные файлы, если их несколько, объединяет и выводит считанные данные в стандартный поток вывода (на экран). С помощью перенаправления потоков (программных каналов) команда cat может быть использована для выполнения разнообразных операций.
Примеры:
1) $ cat > file1
- в файл file1 помещается текст, набираемый на клавиатуре.
Если до этого файл file1 не существовал, он будет создан; если существовал, его первоначальное содержимое будет утрачено. Окончание ввода текста происходит при нажатии комбинации клавиш Ctrl+D.
2) $ cat file1 > file2
- содержимое файла file1 копируется в файл file2. Файл file1 при этом остается без изменений.
3) $ cat file1 file2 > result
- содержимое file2 будет добавлено к содержимому file1 и помещено в файл result.
4) $ cat file1 >> file2
- содержимое файла file1 добавляется в конец файла file2.
cp - копирование файлов:
�$ cp вх_файл_1 [вх_файл_2 [...вх_файл_n]] вых_файл
Эта команда имеет два режима использования:
1. 1. если выходной файл есть обычный файл, то входной файл может быть только один; его содержимое копируется в выходной файл. Если выходной файл существовал, то его старое содержимое утрачивается, а атрибуты защиты остаются; если выходной файл не существовал, то он будет создан и унаследует атрибуты входного файла.
2. 2. если выходной файл есть каталог, то в него скопируются все указанные входные файлы, но каталог естественно должен быть создан заранее.
Пример. Скопировать два файла из текущего каталога в указанный с теми же именами:
$ cp f1.txt f2.txt ../usr/petr
$ ls ../usr/petr
f1.txt
f2.txt
mv - пересылка файлов:
$ mv вх_файл_1 [вх_файл_2 [...вх_файл_n]] вых_файл
Отличие команды пересылки от команды копирования состоит только в том, что входные файлы после выполнения команды уничтожаются.
Пример. Перенести файлы с расширением "c" из указанного каталога в текущий:
$ mv��� petr/*.c����������� .
ln - создание новых ссылок на файл:
����������� $ ln вх_файл_1 [вх_файл_2 [...вх_файл_n]] вых_файл
Эта команда имеет два режима использования:
1. 1. Если выходной файл есть обычный файл, то входной файл может быть только один; в этом случае на него создается ссылка с именем вых_файл и к нему можно обращаться и по имени вх_файл_1, и по имени вых_файл. Количество ссылок на файл в описателе увеличивается на 1.
2. 2. Если выходной файл есть каталог, то в нем создаются элементы, включающие имена всех перечисленных входных файлов и ссылки на них.
Пример:
$ ls
file1
$ ln file1 file2
$ ls
file1
file2
1.3.4. Команды работы с текстовыми файлами
grep - поиск шаблона (подстроки) в файлах:
$ grep [-ключи] подстрока список_файлов
Найденные строки выводятся на стандартный вывод в формате, определяемом ключами. Если файлов несколько, то перед каждой строкой выводится имя соответствующего файла. Ключи:
-c - вывод имен всех файлов с указанием количества строк, содержащих шаблон;
-i - игнорирование регистра (различия строчных и заглавных латинских букв);
-n - вывод перед строкой ее относительного номера в файле;
-v - вывод строк, не содержащих шаблона (инверсия вывода);
-l - вывод только имен файлов, содержащих шаблон.
wc - подсчет количества строк, слов и символов в файлах:
$ wc [-lwc] [список_файлов]
Подсчет строк - ключ -l, слов - ключ -w и символов - ключ -c (по умолчанию -lwc). Если список файлов пуст, то подсчет ведется в стандартном потоке ввода.
sort - сортировка файлов:
$ sort [-ключи] список_файлов
Эта команда сортирует входные файлы по строкам в соответствии с увеличением кодов символов. Ключи:
-r - обратный порядок сортировки;
-f - не учитывать различие строчных и прописных латинских букв
-n - числовой порядок сортировки и т.д.
cmp - вывод места первого расхождения:
$ cmp файл_1 файл_2
Выводит номер символа и номер строки (в текстовых файлах), в которой впервые встречается расхождение во входных файлах. Работает с любыми файлами.
diff - вывод всех расхождений в файлах:
$ diff файл_1 файл_2
Выводит все строки, в которых встречаются расхождения между входными файлами. Работает только с текстовыми файлами.
find - поиск файлов в поддереве каталогов:
find список_каталогов условия_поиска
Команда последовательно просматривает все поддеревья, начинающиеся с одного из каталогов, указанных в списке каталогов, анализирует их атрибуты, и если они удовлетворяют условиям поиска: выполняет действия, заданные в условиях_поиска
В команде может быть задано множество условий поиска, необходимые комбинации которых объединяются в булевское выражение с помощью логических операций:
! условие������������������� отрицание условия;
пробел ���������� ����������� соответствует операции �И�;
-o������������������������������� операция �ИЛИ�;
\( выражение \)�������� булевское выражение в скобках
Перечислим некоторые опции, задающие условия (при этом условимся обозначать через n положительное десятичное число, +n - любое положительное число, строго большее n, -n - любое положительное число, строго меньшее n):
� � -name имя_файла������������������� истинно для файлов с именем имя_файла; в задаваемом имени допускается использование метасимволов;
� � -perm 8-ричный_код�� истинно для файлов с указанным кодом прав доступа;
� � -type {f|d|b|c|p}����������������������� истинно для файлов указанного типа (f - обычный файл, d - каталог, b - блок-ориентированный специальный файл, c - байт-ориентированный специальный файл, p - именованный канал);
� � -print���������������������������� всегда истинно; вызывает печать маршрутного имени файла;
� � -size n[c]���������������������������������� истинно для файлов с длиной n. По умолчанию длина задается в блоках по 512 байт, а если после длины ставится символ c, то в байтах;
� � -exec команда������������� истинно, если команда, выполняющаяся при наличии данного условия, возвращает нулевой код завершения. Если в тексте команды должно быть указано имя текущего проверяемого файла, то вместо него пишут {}. В конце команды должна стоять экранированная точка с запятой: ‘\;’;
� � -links n������������������������� истинно для файлов с числом ссылок n.
Примеры:
$find / -type f -links +1 -print
Выводятся полные маршрутные имена файлов корневого каталога, на которые имеется более одной ссылки.
$find / -type f -size +2 -exec ls -l {}\;
Выводятся листинги с указанием длины в блоках (по 1024 байта) для файлов корневого каталога, длина которых в блоках по 512 байт превышает 2.
$find /dev \( -type d -o -type b \) -print
Выводятся имена каталогов или специальных файлов устройств блок-ориентированного типа из каталога /dev и его подкаталогов
find / -name ‘*.a’ -exec ar -t {} \; |grep console
В этой сложной команде ищутся файлы с расширением ‘.a’ (архивы или библиотеки), происходит просмотр их содержимого (-exec ar -t {}) и выводятся строки, содержащие подстроку ‘console’ (grep console)
Редактирование текстовых файлов. Команда vi
Запуск редактора: vi [+[n]] имя_файла
+�������������������� вывести на экран конец файла;
n�������������������� вывести на экран текст файла, начиная со строки n.
Текстовый полноэкранный редактор vi работает в двух основных режимах: в режиме �ввод текста� и в режиме �команда�.
Режим �ввод текста�
В этот режим редактор переводится с помощью клавиш <a> и <i>:
<a>���������������� набор текста в текущую строку;
<b>���������������� вставка текста в текущую строку перед курсором;
<ESC>���������������������� выход из режима �ввод текста� в режим �команда�.
Режим �команда�
Это - основной режим редактирования текста:
<x>���������������� уничтожение текущего символа, выделенного курсором;
<r>����������������� замена текущего символа на символ, набранный вслед за командой <r>;
<s>���������������� замена одного или нескольких символов текстом. Например: 2sTEXT - замена двух текущих символов на слово TEXT;
<o>���������������� вставить пустую строку после текущей;
[n]<dw>�������� уничтожить текущее слово или n слов;
[n]<dd>��������� уничтожить текущую строку или n строк.
Выход из редактора
<ESC>:wq!��������������� Выход с сохранением;
<ESC>:q!������������������ Выход без сохранения.
1.3.5. Команды работы с процессами
& - запуск процесса как фонового (параллельного):
$ имя_процесса [-ключи] [параметры] &
При выполнении этой команды следующее приглашение ОС появится сразу же после запуска процесса (не дожидаясь его завершения). Фоновый процесс не допускает ввода с клавиатуры и выводит сообщения на экран, нарушая целостность ввода и вывода привилегированного процесса.
nohup - корректный запуск процесса как фонового:
$ nohup имя_процесса [-ключи] [параметры]
Эта команда перенаправляет поток вывода фонового процесса в файл nohup.out.
ps - получить список всех процессов:
$ ps [-ключи]
При отсутствии ключей будет выведен список процессов самого пользователя (идентификатор процесса, номер терминала и время процессора, затраченное на процесс). Ключи:
-e - вывод информации обо всех процессах в системе;
-a - вывод информации о процессах, связанных с данным терминалом;
-l - вывод информации в длинном формате.
kill - послать сигнал процессу:
$ kill -номер_сигнала идентификатор_процесса
Для принудительного завершения процесса ему посылается сигнал номер 9, который невозможно проигнорировать или обработать в процессе никаким иным образом, кроме немедленного завершения.
1.4. ИНТЕРПРЕТАТОР SHELL
Интерпретатор SHELL является оболочкой над всей операционной системой и выполняет интерфейсные функции между пользователем и ОС. Он перехватывает и интерпретирует все команды пользователя: формирует и выводит ответные сообщения.
Помимо запуска на выполнение стандартных команд UNIX и исполняемых файлов, интерпретатор включает собственный язык, который по своим возможностям приближается к высокоуровневым языкам программирования. Этот язык позволяет создавать программы (shell-файлы), которые могут включать операторы языка и команды UNIX. Такие файлы не требуют компиляции и выполняются в режиме интерпретации, но они должны обладать правом на исполнение (устанавливается с помощью команды chmod).
Процедуре shell могут быть переданы аргументы при запуске. Каждому из первых девяти аргументов ставится в соответствие позиционный параметр от $1 до $9 ($0 - имя самой процедуры), и по этим именам к ним можно обращаться из текста процедуры.
Прежде, чем начать рассмотрение некоторых операторов shell, .следует обратить внимание на использование в командах некоторых символов.
\���������� знак отмены специального символа перевода строки, следующего непосредственно вслед за этим знаком.
‘’��������� одинарные кавычки: используются для обрамления текста: передаваемого как единый аргумент команды.
“”�������� двойные кавычки, используются для обрамления текста, содержащего имена переменных для подстановки ($имя) или стандартные команды, заключенные в символы тупого ударения (`команда`).
``��������� символы тупого ударения, служат для выполнения команды, заключенной между ними.
echo��� вывод сообщений.
Пример. Вывод на экран содержимого текущего каталога.
echo “Текущий каталог: \
`pwd` \
`ls`”
Будет выведено:
Текущий каталог: имя_каталога
файл_1
файл_2
. . . . . .
Переменные языка shell
Язык shell позволяет работать с переменными (без предварительного объявления). Имена переменных начинаются с буквы и могут включать буквы и цифры. Обращение к переменным начинается со знака $.
Пример. Переход к начальному каталогу пользователя.
cd $HOME
Оператор присваивания
Присвоение значений переменным осуществляется с помощью оператора ‘=’ без пробелов.
Пример. ������� s=Hello
echo $s
Осуществляется с помощью команды expr и операторов:
����������� арифметических����������������������������� логических
+�������� сложение������������������������������ =��������� равно
-��������� вычитание��������������������������� !-�������� не равно
\*�������� умножение��������������������������� \<�������� меньше
/���������� деление�������������������������������� \<=����� меньше или равно
%������� остаток от деления�������������� \>�������� больше
���������������������������������������������������������� \>=����� больше или равно
Результат операций сравнения - вывод 1 (true) или 0 (false). Все операторы и имена переменных должны отделяться друг от друга пробелами.
Пример.
����������� a=5�� b=12
����������� a=’expr $a + 4’
����������� d=’expr $b - $a’
����������� echo $a $b $d
Будет выведено:
����������� 9 12 3
Ветвление вычислительного процесса осуществляется с помощью оператора if:
����������� if список_команд1
����������� then список_команд2
����������� [else список_команд3]
����������� fi
Список_команд - это одна или несколько команд (для задания пустого списка используется двоеточие - ‘:’). Список_команд1 предает оператору if код возврата последней команды из списка. Если он равен 0, то выполняются команды из списка_команд2, таким образом нулевой код возврата эквивалентен значению �истина�. В противном случае выполняются команды из списка_команд3, если он существует.
Проверка условия может осуществляется с помощью команды test. Аргументами этой команды могут быть имена файлов, числовые и нечисловые строки. Она используется в следующих режимах:
� � проверка файлов:������������������ test -ключ имя_файла
Ключи:���������� -r�������� файл существует и доступен для чтения;
����������������������� -w������� файл существует и доступен для записи;
����������������������� -x�������� файл существует и доступен для исполнения;
����������������������� -f�������� файл существует и имеет тип ‘-‘, т.е. это обычный файл;
����������������������� -s�������� файл существует, имеет тип ‘-‘ и не пуст;
����������������������� -d������� файл существует и имеет тип ‘d‘, т.е. это каталог.
� � сравнение чисел:������������������� test число1 -ключ число2
Ключи:���������� -eq������ равно;
����������������������� -ne������ не равно;
����������������������� -lt������� меньше;
����������������������� -le������� меньше или равно;
����������������������� -gt������ больше
����������������������� -ge������ больше или равно.
� � сравнение строк:
test [-n] строка������������������� строка непуста;
test -z строка���������������������������������� строка пуста;
test строка1 = строка2����� строки равны;
test строка1 != строка2���� строки не равны.
В языке shell есть три типа циклов: while, until и for.
� � цикл while:
while список_команд1{;|перевод строки}
do список_команд2{;|перевод строки}
done
В условии учитывается код возврата последней выполненной команды из списка_команд1, при этом 0 интерпретируется как �истина�.
� � цикл until:
until список_команд1{;|перевод строки}
do список_команд2{;|перевод строки}
done
Проверка условия выполняется перед выполнением цикла. Учитывается код возврата последней выполненной команды из списка_команд1, при этом цикл выполняется до тех пор, пока код возврата не примет значение �истина�.
� � цикл for:
for переменная [in список_значений]{;|перевод строки}
do список_команд{;|перевод строки}
done
Переменной присваивается значение очередного слова из списка_значений и для этого значения выполняется список_команд. Количество итераций равно количеству цепочек символов в списке_значений, разделенных пробелами. Если слово in и список_значений опущены как необязательные, то переменной поочередно присваиваются значения параметров, переданных при запуске данной программы. В качестве списка можно использовать шаблоны имен файлов, тогда интерпретатор превращает этот шаблон в требуемый синтаксисом список имен файлов, удовлетворяющий шаблону.
Пример. Печать списка имен текстовых файлов из текущего каталога.
����������� list=`ls *.txt`
����������� for val in $list
do
����������� echo �$val�
done
Файловая система - это ключевое звено, обеспечившее успешное применение UNIX. Основной особенностью файловой системы UNIX является то, что все, с чем работает ОС UNIX, она воспринимает в виде файла. Таким образом, файл является единой универсальной структурой данных, в рамках которой реализуется любая операция ввода-вывода.
2.1.1. Структура файловой системы
Файловая система ОС UNIX имеет иерархическую структуру, образующую дерево каталогов и файлов. Корневой каталог обозначается символом "/", путь по дереву каталогов состоит из имен каталогов, разделенных "/", например:
/usr/work/document
В каждый момент времени с любым пользователем связан текущий каталог, то есть местоположение пользователя в иерархической файловой системе.
Каждый файл ОС UNIX может быть однозначно специфицирован некоторой структурой данных, называемой описателем файла или дескриптором. Эта структура описана в файле <fcntl.h>, она занимает 64 байта и содержит следующую информацию:
struct dinode
{ unsigned
short di_mode;���������� /* режим доступа и тип файла */
short di_nlink;����������������������� /* счетчик числа ссылок на файл */
short di_uid;�������������� /* идентификатор его владельца */
short di_gid;�������������� /* идентификатор группы */
off_t di_size;������������� /* счетчик числа байт в файле */
char di_addr[40];������ /* указатели на блоки диска,
в которых хранится сам файл */
time_t di_atime;�������� /* дата последнего доступа */
time_t di_mtime;������� /* дата последней модификации метаданных*/
time_t di_ctime;�������� /* дата создания */
}
Поле di_mode состоит из 16-ти разрядов:
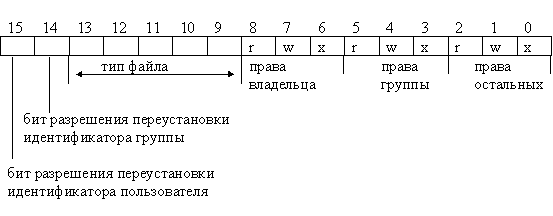
Поле di_addr используется для хранения указателей местоположения блоков диска, содержащих информацию, помещенную в данный файл. В этом поле может храниться 13 указателей, из которых первые 10 относятся к первым десяти блокам файла. Если файл занимает больше места, то в 11-й указатель заносится информация о местоположении первичного блока косвенности, состоящего из ста двадцати восьми 32-битных указателей на блоки файла; 12-й указатель указывает на вторичный блок косвенности, содержащий 128 указателей местоположения первичных блоков косвенности, а 13-й указатель, соответственно, указывает на местоположение третичного блока косвенности, включающего 128 указателей вторичного блока косвенности. Таким образом, используя эту схему адресации, можно обращаться к файлу, состоящему не более чем из (128x128x128+128x128+128+10) блоков. Все эти рассуждения справедливы для блоков размером 512 (128x4) байт.
Обращение к файлу происходит по имени. Локальное имя файла представляет собой набор произвольных символов. Если в среди этих символов встречается точка, то за ней следует так называемое расширение, которое обычно служит для определения типа файла. Например, файлы, хранящие текст, чаще всего имеют расширение "txt" или "doc" (title.doc, book.txt и т.д.), файлы с текстом программ на языке С - расширение "c" (progr.c, code.c и т.п.), исполняемые файлы - расширение "exe" или "out". Расширений может быть несколько (например, имя "progr.c.b" может означать старую версию (bak-файл) программы на языке С).
Локальное имя файла хранится в соответствующем каталоге. Путь к файлу от корневого каталога называется полным именем файла. Если обращение к файлу начинается с символа "/", то его поиск начинается с корневого каталога, в любом другом случае поиск файла начинается с текущего каталога.
У любого файла может быть несколько имен. Фактически, имя файла является ссылкой на файл, специфицированный номером описателя. Таким образом, располагая имена одного и того же файла в разных каталогах можно в каждом каталоге иметь возможность обращаться к файлу напрямую, а не с помощью указания полного пути.
Всякий файл ОС UNIX в соответствии с его типом может быть отнесен к одной из следующих групп: обычные файлы, каталоги, специальные файлы и каналы.
Обычный файл представляет собой последовательность байтов. Никаких ограничений на файл системой не накладывается, и никакого смысла не приписывается его содержимому: смысл байтов зависит исключительно от программ, обрабатывающих файл.
Каталог - это файл особого типа, отличающийся от обычного файла наличием структуры и ограничением по записи: осуществить запись в каталог может только ядро ОС UNIX. Каталог устанавливает соответствие между файлами (точнее, номерами описателей) и их локальными именами. Пример каталога для файловой системы ОС UNIX System V - Рис.2.1 (2 байта - номера описателей, 14 байтов - локальные имена).
|
Номер описателя |
Имя файла |
|
5412 81 3009 58 3413 0 3601 |
. .. bin work text.txt cross.c move.c |
Рисунок 2.1. Пример каталога ОС UNIX System V
Номер описателя, соответствующий имени ".",- это ссылка на файл, в котором содержится информация о самом каталоге. Номер описателя, соответствующий имени "..", - это ссылка на родительский каталог текущего каталога. Совокупность всех каталогов специфицирует структуру файловой системы в целом.
Специальный файл - это файл, поставленный в соответствие некоторому внешнему устройству и имеющий специальную структуру. Его нельзя использовать для хранения данных как обычный файл или каталог, но над ним можно производить те же операции, что и над любым другим. При этом ввод/вывод информации в этот файл будет соответствовать вводу с внешнего устройства или выводу на него.
Канал - это программное средство, связывающее процессы ОС UNIX буфером ввода/вывода. Например, запуск процессов в виде
$ процесс_1 | процесс_2
означает, что стандартный вывод процесса_1 будет замкнут на стандартный ввод процесса_2. При этом сначала создается канал, а потом на выполнение одновременно запускаются оба процесса, и общее время их выполнения определяется более медленным процессом.
ОС UNIX поддерживает операции ввода-вывода с помощью набора взаимосвязанных таблиц. Основной из них считается таблица описателей файлов. Она представляет собой хранящуюся в оперативной памяти ЭВМ структуру данных, элементами которой являются копии описателей файлов, к которым была осуществлена попытка доступа. Каждому элементу таблицы описателей файлов обязательно соответствует один или несколько элементов таблицы файлов. Элемент таблицы файлов содержит информацию о режиме открытия файла и положении указателя чтения-записи. Таким образом, каждый файл может быть одновременно открыт несколькими независимыми процессами, и при каждом открытии файла количество элементов таблицы файлов будет увеличиваться на единицу. Если процессы связаны родственными отношениями, то процесс-потомок, порожденный системным вызовом fork, унаследует все открытые файлы процесса-предка. Это осуществляется с помощью таблицы открытых файлов процесса, которая создается сразу после порождения процесса, содержит информацию только о файлах, открытых данным процессом, и передается процессу-потомку в момент его порождения.
Для примера рассмотрим следующую последовательность системных вывозов:
fd1 = open("/etc/passwd",O_RDONLY);
fd2 = open("local",O_RDWR);
fd3 = open("/etc/passwd",O_WRONLY);
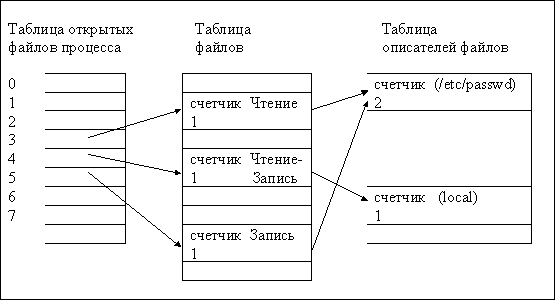
Рисунок 2.2. Структуры данных после открытия
На Рис.2.2 показана взаимосвязь между таблицей описателей файлов, таблицей файлов и таблицей открытых файлов процесса. Каждый вызов функции open возвращает процессу дескриптор файла, а соответствующая запись в таблице открытых файлов процесса указывает на уникальную запись в таблице файлов ядра, даже если один и тот же файл ("/etc/passwd") открывается дважды. Записи в таблице файлов для всех экземпляров одного и того же открытого файла указывают на одну запись в таблице описателей файлов, хранящихся в памяти. Процесс может обращаться к файлу "/etc/passwd" с чтением или записью, но только через дескрипторы файла, имеющие значения 3 и 5 (см. Рис.3). Ядро запоминает разрешение на чтение или запись в файл в строке таблицы файлов, выделенной во время выполнения функции open. Предположим, что второй процесс выполняет следующий набор операторов:
fd1 = open("/etc/passwd",O_RDONLY);
fd2 = open("private",O_RDONLY);
На Рис.2.3 показана взаимосвязь между соответствующими структурами данных, когда оба процесса (и больше никто) имеют открытые файлы. Снова результатом каждого вызова функции open является выделение уникальной точки входа в таблице открытых файлов процесса и в таблице файлов ядра, и при этом ядро хранит не более одной записи на каждый файл в таблице описателей файлов, размещенных в памяти.
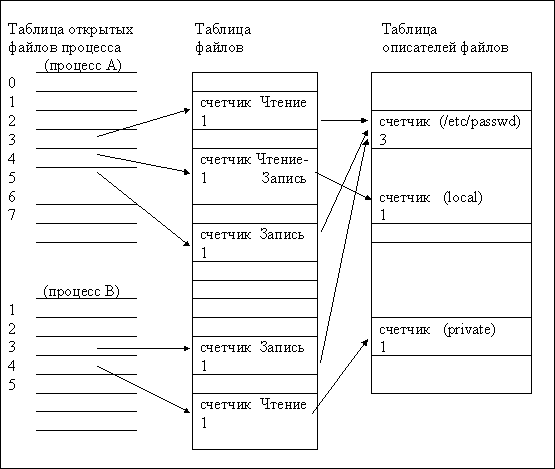
Рисунок 2.3. Структуры данных после того, как два независимых процесса произвели открытие файлов
Запись в таблице открытых файлов процесса по умолчанию хранит смещение в файле до адреса следующей операции ввода/вывода и указывает непосредственно на точку входа в таблице описателей для файла, устраняя необходимость в отдельной таблице файлов ядра.
Вышеприведенные примеры показывают взаимосвязь между записями таблицы открытых файлов процесса и записями в таблице файлов ядра типа �один к одному�. Однако таблица файлов, реализованная как отдельная структура, позволяет совместно использовать один и тот же указатель смещения нескольким пользовательским дескрипторам файла. В системных вызовах dup (см. раздел �Программирование операций ввода-вывода�) и fork (лабораторная работа N 3) при работе со структурами данных допускается такое совместное использование.
Первые три пользовательских дескриптора (0, 1 и 2) именуются дескрипторами файлов стандартного ввода, стандартного вывода и стандартного файла ошибок. Процессы в системе UNIX по договоренности используют дескриптор файла стандартного ввода при чтении вводимой информации, дескриптор файла стандартного вывода при записи выводимой информации и дескриптор стандартного файла ошибок для записи сообщений об ошибках. В операционной системе нет никакого указания на то, что эти дескрипторы файлов являются специальными. Группа пользователей может условиться о том, что файловые дескрипторы, имеющие значения 4, 6 и 11, являются специальными, но более естественно начинать отсчет с 0 (как в языке Си). Принятие соглашения сразу всеми пользовательскими программами облегчает связь между ними при использовании каналов.
Обычно операторский терминал служит и в качестве стандартного ввода, и в качестве стандартного вывода, и в качестве стандартного устройства вывода сообщений об ошибках.
Вызов fork порождает процесс, являющийся потомком по отношению к тому процессу, из которого осуществлен вызов. Процесс-потомок является точной копией процесса-предка за исключением номера самого процесса и значения, возвращаемого вызовом fork. При этом потомок получает к ранее открытым файлам доступ того же типа, что и предок. Родственные процессы общаются с общим файлом через один указатель чтения/записи, и если один из процессов прочитал или записал данные в файл, то значение указателя чтения/записи изменится для всех родственных процессов, имеющих доступ к этому файлу. Естественно, это не относится к файлам, которые были открыты родственными процессами после вызова fork: в этом случае каждый процесс обращается к файлу через собственный указатель.
Для примера рассмотрим следующую последовательность системных вызовов и состояние файловых таблиц после их выполнения (Рис.4):
fd1 = open("/etc/passwd",O_RDONLY);
pid = fork();
fd2 = open("private",O_RDWR);
Первый вызов open выполняется до вызова fork, он создает записи, относящиеся к файлу /etc/passwd, во всех файловых таблицах. При выполнении вызова fork процесс-потомок получает копию таблицы открытых файлов процесса, а в записях таблиц файлов и описателей файлов счетчики ссылок на файл /etc/passwd увеличиваются и становятся равным 2. Дополнительная запись в таблицу файлов не добавляется, оба процесса имеют доступ к файлу через один указатель чтения/записи. Второй вызов open выполняется после вызова fork, то есть тогда, когда существуют уже два процесса - предок и потомок. Каждый из них выполняет открытие файла независимо от другого, поэтому новые записи добавляются во все таблицы (запись в таблице описателей одна на файл, но счетчик ссылок на файл равен числу открывших файл процессов).
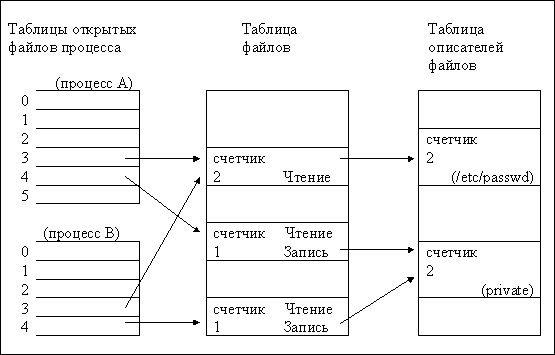
Рисунок 2.4. Структуры данных после того, как два родственных процесса произвели открытие файлов
Закрытие файла уменьшает число ссылок на файл, и только когда оно становится равным 0, происходит удаление соответствующих записей из таблиц.
2.3. ПРОГРАММИРОВАНИЕ ОПЕРАЦИЙ ВВОДА-ВЫВОДА
Системные вызовы представляют собой единственное средство, реализующее интерфейс между пользовательскими программами и ядром ОС UNIX. Всякая операция ввода/вывода для пользователя - это операция ввода/вывода в файл. Рассмотрим наиболее часто используемые из системных вызовов.
OPEN
Открывает файл для получения доступа к нему:
int open(char *pathname, int flags, mode_t mode);
Возвращает положительное целое число, так называемый пользовательский дескриптор файла fd, который в дальнейшем используется для обращения к этому файлу. pathname - указатель на строку символов, содержащую полное имя файла. mode - режим открытия файла (по чтению, записи и др.) Если нет возможности открыть файл, open возвращает -1. flags определяет режим открытия файла (O_CREAT, O_TRUNC, O_RDONLY, O_WRONLY и т.д.), mode задает права доступа к создаваемому файлу.
CLOSE
Закрывает файл, уничтожает связь между пользовательским дескриптором файла и самим файлом:
void close(int fd);
Параметр fd - дескриптор файла, возвращенный вызовом open.
STAT и FSTAT
Эти системные вызовы позволяют получить информацию о файле, не осуществляя явного доступа к нему:
int stat(char *path, struct stat *statbuf);
int fstat(int fd, struct stat *statbuf);
Вызов stat предоставляет информацию по имени файла, а fstat - по номеру дескриптора открытого файла. Информация помещается в структуру, описанную ниже:
struct stat
{��������� dev_t st_dev;
ino_t st_ino;
ushort st_mode;�������� /* режим доступа и тип файла */
short st_nlink;����������� /* счетчик числа ссылок на файл */
ushort st_uid;������������ /* идентификатор его владельца */
ushort st_gid;������������ /* идентификатор группы */
dev_t st_rdev;����������������������� /* тип устройства */
off_t st_size;������������� /* размер файла в байтах */
time_t st_atime;�������� /* дата последнего доступа */
time_t st_mtime;������� /* дата последней модификации */
time_t st_ctime;�������� /* дата создания */
}
Для детализации информации в поле st_mode используются следующие макросы:
#define���������� S_IFMT��������� 0170000��������� /* тип файла */
#define���������� S_IFDIR������� 0040000��������� /* каталог */
#define���������� S_IFCHR������ 0020000��������� /* байт-ориентированный спец. файл */
#define���������� _IFBLK��������� 0060000��������� /* блок-ориентированный спец. файл */
#define���������� S_IFREG������ 0100000��������� /* обычный файл */
#define���������� S_IFIFO�������� 0010000��������� /* дисциплина FIFO */
#define���������� S_ISUID������� 04000������������� /* идентификатор владельца */
#define���������� S_ISGID������� 02000������������� /* идентификатор группы */
#define���������� S_ISVTX������ 01000������������� /* сохранить свопируемый текст */
#define���������� S_IREAD������ 00400������������� /* владельцу разрешено чтение */
#define���������� S_WRITE������ 00200������������� /* владельцу разрешена запись */
#define���������� S_IEXEC������ 00100������������� /* владельцу разрешено исполнение */
Пример использования вызова stat:
struct stat stbuf;
char *filename = ”myfile”;
�. . . . . . . . . . . .
stat(filename, &stbuf);
if ((stbuf.st_mode & S_IFMT) == S_IFDIR)
printf("%s является каталогом", filename);
READ
Осуществляет чтение из открытого файла указанного количества символов в буфер:
int read(int fd, void *buffer, unsigned count);
Возвращает количество реально прочитанных байт num или отрицательный код ошибки.
WRITE
Осуществляет запись в открытый файл указанного количества символов из буфера:
int write(int fd, void *buffer, unsigned count);
Возвращает количество реально записанных байт num или отрицательный код ошибки.
LSEEK
Перемещает указатель файла с пользовательским дескриптором fd на offset байт:
long lseek(int fd, long offset, int fromwhere);
Параметр fromwhere определяет положение указателя файла перед началом перемещения: �������� SEEK_SET - от начала файла;
SEEK_CUR - от текущей позиции указателя;
SEEK_END - от конца файла.
DUP и DUP2
Эти системные вызовы дублируют пользовательский дескриптор файла:
int dup(int handle);
int dup2(int oldhandle, int newhandle);
fd1 = dup(handle);
fd2 = dup2(oldhandle, newhandle);
Копия пользовательского дескриптора позволяет осуществлять к файлу доступ того же типа и с использованием того же указателя чтения/записи, что и с помощью оригинального дескриптора.
Вызов dup возвращает первый свободный номер дескриптора fd1 или -1, если указанный дескриптор handle не соответствует открытому файлу или нет свободных номеров.
Вызов dup2 возвращает дескриптор newhandle как копию дескриптора oldhandle или -1, если указанный дескриптор oldhandle не соответствует открытому файлу. Если newhandle до этого указывал на открытый файл, этот файл в результате вызова dup2 будет закрыт.
2.4. ПРИМЕРЫ ПРОГРАММ РАБОТЫ С ФАЙЛАМИ
Пример 1. Запись в файл / чтение из файла.
Обратите внимание на обработку параметров командной строки.
/*
Фрагмент программы RW.C записи в файл / чтения из файла.
Программа воспринимает в качестве параметра командной
строки имя рабочего файла. Если файл не существует, он будет
создан, если существует, его содержимое будет изменено
*/
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int fd;
int f1()
{
static int j = 1;
if (j > 10) return 0;
write(fd, &j, sizeof(int));
printf("write %d -- %d\n", fd, j++);
return 1;
}
void f2()
{
int i;
lseek(fd,-sizeof(int), 1);
read(fd, &i, sizeof(int));
printf("read %d -- %d\n", fd, i);
}
void main(int argc, char *argv[])
{
if (argc < 2) puts("Format: rw filename");
else
{
����������������������� fd = open(argv[1], O_CREAT | O_RDWR);
����������������������� while (f1()) f2();
����������������������� close(fd);
}
exit(0);
}
Пример 2. Дублирование дескриптора файла.
/*
Фрагмент программы DUP.C - перенаправление стандартного
вывода в файл.
*/
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <fcntl.h>
void main(void)
{
int outf, std_out;
char *str1 = "Вывод строки в файл ",
*str2 = "Вывод строки на экран";
std_out = dup(1);
/* закрытие стандартного вывода */
close(1);
outf = open("1.dat", O_WRONLY);
puts(str1);
write(std_out,str2,strlen(str2));
/* восстановление предыдущих значений */
close(outf);
outf = open("dev\tty", O_WRONLY);
close(std_out);
exit(0);
}
3. ПРОЦЕССЫ И СИГНАЛЫ ОС UNIX
Работу ОС UNIX можно представить в виде функционирования множества взаимосвязанных процессов.
Процесс - это задание в ходе его выполнения. Он представляет собой исполняемый образ программы, включающий отображение в памяти исполняемого файла, полученного в ходе компиляции, стек, код и данные библиотек, а также ряд структур данных ядра, необходимых для управления процессом. Выполнение процесса заключается в точном следовании набору инструкций, который является замкнутым и не передает управление набору инструкций другого процесса. Он считывает и записывает информацию в раздел данных и в стек, но ему недоступны данные и стеки других процессов.
ОС UNIX является многозадачной системой, поэтому в ней параллельно выполняется множество процессов, их выполнение планируется ядром. Несколько процессов могут быть экземплярами одной программы. Процессы взаимодействуют с другими процессами и с вычислительными ресурсами только посредством обращений к операционной системе, которая эффективно распределяет системные ресурсы между активными процессами.
Выполнение процесса осуществляется ядром. Подсистема управления процессами отвечает за синхронизацию процессов, взаимодействие процессов, распределение памяти и планирование выполнения процессов.
С практической точки зрения процесс в системе UNIX является объектом, создаваемым в результате выполнения системного вызова fork. Каждый процесс, за исключением нулевого, порождается в результате запуска другим процессом операции fork. Процесс, запустивший операцию fork, называется родительским, а вновь созданный процесс - порожденным. Каждый процесс имеет одного родителя, но может породить много процессов. Ядро системы идентифицирует каждый процесс по его номеру, который называется идентификатором процесса (PID). Нулевой процесс является особенным процессом, который создается �вручную� в результате загрузки системы. Процесс 1, известный под именем init, является предком любого другого процесса в системе и связан с каждым процессом.
Пользователь, транслируя исходный текст программы, создает исполняемый файл, который состоит из нескольких частей:
- - набора �заголовков�, описывающих атрибуты файла;
- - текста программы;
- - представления на машинном языке данных, имеющих начальные значения при запуске программы на выполнение, и указания на то, сколько пространства памяти ядро системы выделит под неинициализированные данные, так называемые bss (�block started by symbol� - �блок, начинающийся с символа�);
- - других секций, таких как информация символических таблиц.
Ядро загружает исполняемый файл в память при выполнении системной операции exec, при этом загруженный процесс состоит по меньшей мере из трех частей, так называемых областей: текста, данных и стека. Области текста и данных соответствуют секциям текста и bss-данных исполняемого файла, а область стека создается автоматически и ее размер динамически устанавливается ядром системы во время выполнения.
Процесс в системе UNIX может выполняться в двух режимах - режиме ядра или режиме задачи. В режиме задачи процесс выполняет инструкции прикладной программы, системные структуры данных ему недоступны.
Когда процесс выполняет специальную инструкцию (системный вызов), он переключается в режим ядра. Каждой системной операции соответствует точка входа в библиотеке системных операций; библиотека системных операций написана на языке ассемблера и включает специальные команды прерывания, которые, выполняясь, порождают �прерывание�, вызывающее переключение аппаратуры в режим ядра. Процесс ищет в библиотеке точку входа, соответствующую отдельной системной операции, подобно тому, как он вызывает любую из функций.
Соответственно и образ процесса состоит из двух частей: данных режима ядра и режима задачи. В режиме ядра образ процесса включает сегменты кода, данных, библиотек и других структур, к которым он может получить непосредственный доступ. Образ процесса в режиме ядра состоит из структур данных, недоступных процессу в режиме задачи (например, состояния регистров, таблицы для отображения памяти и т.п.).
Каждому процессу соответствует точка входа (запись) в таблице процессов ядра, кроме того, каждому процессу выделяется часть оперативной памяти, отведенной под задачи пользователей. Таблица процессов включает в себя указатели на промежуточную таблицу областей процессов, точки входа в которую служат в качестве указателей на собственно таблицу областей. Областью называется непрерывная зона адресного пространства, выделяемая процессу для размещения текста, данных и стека. Точки входа в таблицу областей описывают атрибуты области, как например, хранятся ли в области текст программы или данные, закрытая ли эта область или же совместно используемая, и где конкретно в памяти размещается содержимое области. Внешний уровень косвенной адресации (через промежуточную таблицу областей, используемых процессами, к собственно таблице областей) позволяет независимым процессам совместно использовать области.
Когда процесс запускает системную операцию exec, ядро системы выделяет области под ее текст, данные и стек, освобождая старые области, которые использовались процессом. Если процесс запускает операцию fork, ядро удваивает размер адресного пространства старого процесса, позволяя процессам совместно использовать области, когда это возможно, и, с другой стороны, производя физическое копирование. Если процесс запускает операцию exit, ядро освобождает области, которые использовались процессом. На Рис.3.1 изображены информационные структуры, связанные с запуском процесса. Таблица процессов ссылается на промежуточную таблицу областей, используемых процессом, в которой содержатся указатели на записи в собственно таблице областей, соответствующие областям для текста, данных и стека процесса.
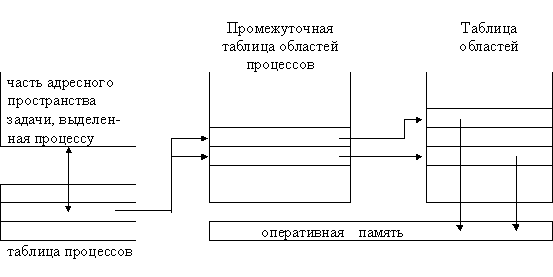
Рисунок 3.1. Информационные структуры для процессов
UNIX является системой разделения времени, это означает, что каждому процессу вычислительные ресурсы выделяются на ограниченный промежуток времени, после чего они предоставляются другому процессу. Максимальный временной интервал, на который процесс может захватить процессор, называется временным квантом. Таким образом, создается иллюзия того, что процессы работают одновременно, хотя в действительности на однопроцессорной машине одновременно может выполняться только один процесс.
Процессы предъявляют различные требования к системе с точки зрения их планирования и общей производительности. Можно выделить три основных класса приложений:
- - интерактивные приложения (командные интерпретаторы, редакторы и проч.). Большую часть времени они проводят в ожидании пользовательского ввода, но для них критично время отклика (реакции системы на ввод данных).
- - фоновые приложения (не требующие вмешательства пользователя). Основной показатель эффективности для них - минимальное суммарное время выполнения в системе.
- - приложения реального времени. Они обычно привязаны к таймеру и требуют гарантированного времени совершения той или иной операции и времени отклика.
В основе планирования выполнения процессов лежат два понятия: квант времени и приоритет. Каждый процесс имеет два атрибута приоритета: текущий (на основании которого осуществляется планирование) и относительный, который задается при порождении процесса и влияет на текущий. Номера приоритетов разбиваются на несколько групп: для процессов в режиме задачи, в режиме ядра, для процессов реального времени (группы указаны в соответствии с повышением приоритета).
Обработчик прерываний от таймера, в частности, проверяет истечение временного кванта для процессов и пересчитывает приоритеты процессов: чем дольше процесс занимает процессор, тем ниже (в пределах группы) становится его приоритет.
Выполнение процесса может быть прервано:
а) планировщиком процессов по истечении временного кванта или в том случае, если в очереди готовых к исполнению процессов есть процесс с более высоким приоритетом.
б) ядром системы, если процесс ожидает недоступного ресурса или окончания длительной операции ввода/вывода.
В режиме ядра приоритет процесса повышается для того, чтобы его выполнение не могло быть прервано, так как это может привести к нарушению целостности структур данных ядра. Таким образом, выполнение системных вызовов осуществляется в непрерывном режиме (за исключением некоторых аппаратных прерываний).
Под контекстом процесса понимается вся информация, для описания процесса. Контекст процесса состоит из нескольких частей:
- - адресное пространство процесса в режиме задачи (код, данные и стек процесса, а также разделяемая память и данные динамических библиотек);
- - управляющая информация (структуры proc и user - запись таблицы процессов и дополнительная информация соответственно);
- - окружение процесса (системные переменные, например, домашний каталог, имя пользователя и др.);
- - аппаратный контекст (значения используемых машинных регистров).
Текст операций системы и ее глобальные информационные структуры совместно используются всеми процессами, но не являются составной частью контекста процесса. Принято говорить, что при запуске процесса система исполняется в контексте процесса. Когда ядро системы решает запустить другой процесс, оно выполняет переключение контекста с тем, чтобы система исполнялась в контексте другого процесса. Ядро осуществляет переключение контекста только при определенных условиях (см.п.1.1.3). Выполняя переключение контекста, ядро сохраняет информацию, достаточную для того, чтобы позднее переключиться вновь на прерванный процесс и возобновить его выполнение.
Аналогичным образом, при переходе из режима задачи в режим ядра, ядро системы сохраняет информацию, достаточную для того, чтобы позднее вернуться в режим задачи и продолжить выполнение с прерванного места. Однако, переход из режима задачи в режим ядра является сменой режима, но не переключением контекста. Ядро меняет режим выполнения с режима задачи на режим ядра и наоборот, оставаясь в контексте одного процесса.
Ядро обрабатывает прерывания в контексте прерванного процесса, пусть даже оно и не вызывало никакого прерывания. Прерванный процесс мог при этом выполняться как в режиме задачи, так и в режиме ядра. Ядро сохраняет информацию, достаточную для того, чтобы можно было позже возобновить выполнение прерванного процесса, и обрабатывает прерывание в режиме ядра. Ядро не порождает и не планирует порождение какого-то особого процесса по обработке прерываний.
Время жизни процесса можно разделить на несколько состояний, каждое из которых имеет определенные характеристики, описывающие процесс. Перечислим основные из состояний:
1. 1. Процесс выполняется в режиме задачи.
2. 2. Процесс выполняется в режиме ядра.
3. 3. Процесс не выполняется, но готов к выполнению, находится в очереди готовых к исполнению процессов и ждет, когда планировщик выберет его. Естественно, в этом состоянии может находиться много процессов, и алгоритм планирования устанавливает, какой из процессов будет выполняться следующим.
4. 4. Процесс приостановлен (�спит�). Процесс �впадает в сон�, когда он не может больше продолжать выполнение, например, когда ждет завершения ввода-вывода или освобождения какого-либо занятого ресурса.
Поскольку процессор в каждый момент времени выполняет только один процесс, в состояниях 1 и 2 может находиться самое большее один процесс.
Состояния процесса, перечисленные выше, дают статическое представление о процессе, однако процессы непрерывно переходят из состояния в состояние в соответствии с определенными правилами. Диаграмма переходов представляет собой ориентированный граф, вершины которого представляют собой состояния, в которые может перейти процесс, а дуги - события, являющиеся причинами перехода процесса из одного состояния в другое. Переход между двумя состояниями разрешен, если существует дуга из первого состояния во второе. Несколько дуг может выходить из одного состояния, однако процесс переходит только по одной из них в зависимости от того, какое событие произошло в системе. На Рис.3.2 представлена диаграмма переходов для состояний, перечисленных выше.
В режиме разделения времени может выполняться одновременно несколько процессов. Если им разрешить свободно выполняться в режиме ядра, то они могут испортить глобальные информационные структуры, принадлежащие ядру. Запрещая произвольное переключение контекстов и управляя возникновением событий, ядро защищает свою целостность. Ядро разрешает переключение контекста только тогда, когда процесс переходит из состояния �запуск в режиме ядра� в состояние �сна в памяти�. Процессы, запущенные в режиме ядра, не могут быть выгружены другими процессами; поэтому иногда говорят, что ядро невыгружаемо, при этом процессы, находящиеся в режиме задачи, могут выгружаться системой. Ядро поддерживает целостность своих информационных структур, поскольку оно невыгружаемо, таким образом решая проблему �взаимного исключения� - обеспечения того, что критические секции программы выполняются в каждый момент времени в рамках самое большее одного процесса.
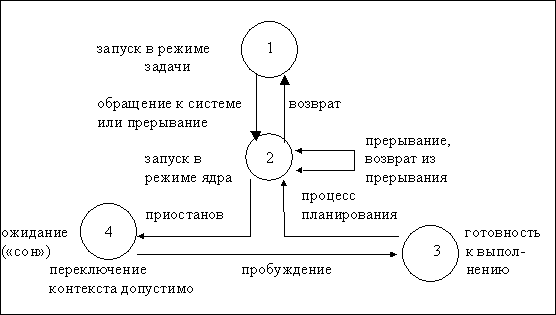
Рисунок 3.2. Состояния процесса и переходы между ними
3.1.3. Сигналы как средство взаимодействия процессов
Сигнал - это программное средство, с помощью которого может быть прервано функционирование процесса ОС UNIX. Сигналы сообщают процессам о возникновении асинхронных событий. Механизм сигналов позволяет процессам реагировать на различные события, которые могут происходить в ходе работы процесса внутри него самого или во внешней среде.
Сигналы описаны в файле <signal.h>, каждому из них ставится в соответствие мнемоническое обозначение. Количество и семантика сигналов зависят от версии ОС UNIX.
В версии System V сигналы имеют номера от 1 до 19:
#define NSIG����������� 20
#define SIGHUP������ 1��������� /* разрыв связи */
#define SIGINT�������� 2��������� /* прерывание */
#define SIGQUIT����� 3��������� /* аварийный выход */
#define SIGILL�������� 4��������� /* неверная машинная инструкция */
#define SIGTRAP���� 5��������� /* прерывание-ловушка */
#define SIGIOT�������� 6��������� /* прерывание ввода-вывода */
#define SIGEMT������ 7��������� /* программное прерывание EMT */
#define SIGFPE������� 8��������� /* авария при выполнении операции с */
/* плавающей точкой */
#define SIGKILL����� 9��������� /* уничтожение процесса */
#define SIGBUS������ 10������� /* ошибка шины */
#define SIGSEGV���� 11������� /* нарушение сегментации */
#define SIGSYS������� 12������� /* ошибка выполнения системного вызова */
#define SIGPIPE������ 13������� /* запись в канал есть, чтения нет */
#define SIGALRM��� 14������� /* прерывание от таймера */
#define SIGTERM��� 15������� /* программ. сигнал завершения от kill */
#define SIGUSR1���� 16������� /* определяется пользователем */
#define SIGUSR2���� 17������� /* определяется пользователем */
#define SIGCLD������ 18������� /* процесс-потомок завершился */
#define SIGPWR������ 19������� /* авария питания */
#define SIG_DFL����� (int(*)())0������� /* все установки �по умолчанию� */
#define SIG_IGN����� (int(*)())1������� /* игнорировать этот сигнал */
В версии BSD UNIX сигналы описываются следующим образом:
#define SIGHUP������ 1��������� /* разрыв связи */
#define SIGINT�������� 2��������� /* прерывание */
#define SIGQUIT����� 3��������� /* аварийный выход */
#define SIGILL�������� 4��������� /* неверная машинная инструкция */
#define SIGTRAP���� 5��������� /* прерывание-ловушка */
#define SIGIOT�������� 6��������� /* прерывание ввода-вывода */
#define SIGABRT���� 6��������� /* используется как ABORT */
#define SIGEMT������ 7��������� /* программное прерывание EMT */
#define SIGFPE������� 8��������� /* авария при выполнении операции
��� с плавающей точкой */
#define SIGKILL����� 9��������� /* уничтожение процесса (не может быть
��� перехвачен или проигнорирован */
#define SIGBUS������ 10������� /* ошибка шины */
#define SIGSEGV���� 11������� /* нарушение сегментации */
#define SIGSYS������� 12������� /* неправильный аргумент системного
��� вызова */
#define SIGPIPE������ 13������� /* запись в канал есть, чтения нет */
#define SIGALRM��� 14������� /* прерывание от таймера */
#define SIGTERM��� 15������� /* программ. сигнал завершения от kill */
#define SIGUSR1���� 16������� /* определяется пользователем */
#define SIGUSR2���� 17������� /* определяется пользователем */
#define SIGCLD������ 18������� /* изменение статуса потомка
��� (завершение процесса-потомка) */
#define SIGCHLD��� 18������� /* альтернатива для SIGCLD (POSIX) */
#define SIGPWR������ 19������� /* авария питания */
#define SIGWINCH 20������� /* изменение размера окна */
#define SIGURG������ 21������� /* urgent socket condition */
#define SIGPOLL���� 22������� /* pollable event occured */
#define SIGIO���������������������� SIGPOLL������ /* socket I/O possible (SIGPOLL alias) */
#define SIGSTOP����� 23������� /* стоп (не может быть перехвачен или
��� проигнорирован */
#define SIGTSTP����� 24������� /* требование остановки от терминала */
#define SIGCONT��� 25������� /* остановить процесс с возможностью
��� продолжения */
#define SIGTTIN����� 26������� /* скрытая попытка чтения с терминала */
#define SIGTTOU���� 27������� /* скрытая попытка записи на терминал */
#define SIGVTALRM��������� 28������� /* виртуальное время истекло */
#define SIGPROF���� 29������� /* время конфигурирования истекло */
#define SIGXCPU��� 30������� /* превышен лимит ЦП */
#define SIGXFSZ���� 31������� /* превышен лимит размера файла */
#define SIGWAITING 32��������������� /* process's lwps заблокирован */
#define SIGLWP������ 33������������������� /* спецсигнал (used by thread library) */
#define SIGFREEZE����������� 34������������������� /* спецсигнал, используемый процессором*/
#define SIGTHAW�� 35������������������� /* спецсигнал, используемый процессором*/
#define _SIGRTMIN����������� 36������������������� /* первый (с высшим приоритетом)
��� сигнал реального времени */
#define _SIGRTMAX���������� 43������������������� /* последний (с низшим приоритетом)
��� сигнал реального времени */
#define SIG_DFL����� (void(*)())0���� /* все установки �по умолчанию� */
#define SIG_IGN����� (void(*)())0���� /* игнорировать этот сигнал */
Примечание: причины возникновения сигналов для различных версий могут отличаться; первоначально они были обусловлены архитектурными особенностями ЭВМ PDP-11.
Причины возникновения сигналов
В версии System V UNIX возникновение сигналов можно классифицировать следующим образом:
- - введение пользователем управляющего символа с терминала всем процессам, ассоциированным с данным терминалом (SIGINT, SIGQUIT, SIGHUP);
- - возникновение аварийной ситуации при функционировании пользовательского процесса (SIGILL, SIGTRAP, SIGFPE, SIGBUS, SIGSEGV, SIGSYS, SIGPIPE);
- - возникновение непредусмотренного или не поддающегося идентификации события (SIGTERM, SIGCLD, SIGPWR);
- - возникновение некоторого заранее описанного события (SIGALRM).
Посылка сигналов производится процессами - друг другу, с помощью функции kill, - или ядром. Для каждого процесса определен бинарный вектор, длина которого равна количеству сигналов в системе. При получении процессом сигнала I соответствующий i-й разряд этого вектора становится равным 1. Каждому сигналу соответствует адрес функции, которая будет вызвана для обработки данного сигнала.
Ядро обрабатывает сигналы в контексте того процесса, который получает их, поэтому чтобы обработать сигналы, нужно запустить процесс.
Существует три способа обработки сигналов:
- - реакция по умолчанию,
- - игнорирование сигнала,
- - выполнение особой (пользовательской) функции по его получении.
Реакцией по умолчанию со стороны процесса, исполняемого в режиме ядра, обычно является вызов функции exit(), т.е. завершение процесса. Но вместе с тем реакция процесса на принимаемый сигнал зависит от того, как сам процесс определил свое поведение в случае приема данного сигнала: процесс может проигнорировать сигнал, вызвать на выполнение другой процесс и т.д. При этом способ обработки сигналов одного типа не влияет на обработку сигналов других типов.
Обрабатывая сигнал, ядро определяет тип сигнала и очищает (гасит) разряд в записи таблицы процессов, соответствующий данному типу сигнала и установленный в момент получения сигнала процессом. Таким образом, когда процесс получает любой неигнорируемый им сигнал (за исключением SIGILL и SIGTRAP), ОС UNIX автоматически восстанавливает реакцию �по умолчанию� на всякое последующее получение этого сигнала.
Замечание 1: Если необходима многократная обработка одного и того же сигнала, процесс должен каждый раз осуществлять системный вызов signal для установления требуемой реакции на данный сигнал.
Замечание 2: Процесс не в состоянии узнать, сколько однотипных сигналов им было получено. В том случае, если процесс не успевает обработать все поступившие сигналы, происходит потеря информации.
Если функции обработки сигнала присвоено значение по умолчанию, ядро в отдельных случаях перед завершением процесса сбрасывает на внешний носитель (дампирует) образ процесса в памяти. Дампирование удобно для программистов тем, что позволяет установить причину завершения процесса и посредством этого вести отладку программ. Ядро дампирует состояние памяти при поступлении сигналов, которые сообщают о каких-нибудь ошибках в выполнении процессов, как например, попытка исполнения запрещенной команды или обращение к адресу, находящемуся за пределами виртуального адресного пространства процесса. Ядро не дампирует состояние памяти, если сигнал не связан с программной ошибкой, за исключением внешнего сигнала о выходе (quit), обычно вызываемого одновременным нажатием клавиш Ctrl+|.
Если процесс получает сигнал SIGINT, который было решено игнорировать (signal(SIGINT,SIG_IGN)), выполнение процесса продолжается так, словно сигнала и не было. Поскольку ядро не сбрасывает значение соответствующего поля, свидетельствующего о необходимости игнорирования сигнала данного типа, то когда сигнал поступит вновь, процесс опять не обратит на него внимание.
В том случае, если процесс получает сигнал, реагирование на который установлено системным вызовом signal, сразу по возвращении процесса в режим задачи выполняется заранее условленное действие, описанное в вызове signal. После выполнения функции обработки сигнала управление будет передано на то место в программе пользователя, где было произведено обращение к системной функции или произошло прерывание.
Если во время исполнения системной функции приходит сигнал, а процесс приостановлен с допускающим прерывания приоритетом, этот сигнал побуждает процесс выйти из приостанова, вернуться в режим задачи и вызвать функцию обработки сигнала. Когда функция обработки сигнала завершается, процесс выходит из системной функции с ошибкой, сообщающей о прерывании ее выполнения. После этого пользователь может запустить системную функцию повторно.
Несмотря на то, что в системе UNIX процессы идентифицируются уникальным кодом (PID), системе иногда приходится использовать для идентификации процессов номер �группы�, в которую они входят. Например, процессы, имеющие общего предка в лице регистрационного интерпретатора shell, взаимосвязаны, и поэтому когда пользователь нажимает клавиши �delete� или �break�, или когда терминальная линия �зависает�, все эти процессы получают соответствующие сигналы. Ядро использует код группы процессов для идентификации группы взаимосвязанных процессов, которые при наступлении определенных событий должны получать общий сигнал. Код группы запоминается в таблице процессов. При выполнении функции fork процесс-потомок наследует код группы своего родителя.
Для того, чтобы образовать новую группу процессов, следует воспользоваться системной функцией setpgrp:
grp = setpgrp();
где grp - новый код группы процессов, равный его коду идентификации процесса, осуществившего вызов setpgrp().
3.2.1. Системные вызовы для работы с процессами
Рассмотрим системные вызовы, используемые при работе с процессами в ОС UNIX, описанные в библиотеке <fcntl.h>.
Системный вызов fork создает новый процесс, копируя вызывающий; вызов exit завершает выполнение процесса; wait дает возможность родительскому процессу синхронизировать свое продолжение с завершением порожденного процесса, а sleep приостанавливает на определенное время выполнение процесса. Системный вызов exec дает процессу возможность запускать на выполнение другую программу.
FORK
Создание нового процесса:
int fork(void);
pid = fork();
В ходе выполнения функции ядро производит следующую последовательность действий:
1. 1. Отводит место в таблице процессов под новый процесс.
2. 2. Присваивает порождаемому процессу уникальный код идентификации.
3. 3. Делает копию контекста родительского процесса. Поскольку те или иные составляющие процесса, такие как область команд, могут разделяться другими процессами, ядро может иногда вместо копирования области в новый физический участок памяти просто увеличить значение счетчика ссылок на область.
4. 4. Увеличивает значения счетчика числа файлов, связанных с процессом, как в таблице файлов, так и в таблице индексов.
5. 5. Возвращает родительскому процессу код идентификации порожденного процесса, а порожденному процессу - 0.
В результате выполнения функции fork пользовательский контекст и того, и другого процессов совпадает во всем, кроме возвращаемого значения переменной pid. Если процесс не может быть порожден, функция возвращает отрицательный код ошибки.
Процесс, вызывающий функцию fork, называется родительским (процесс-родитель или процесс-предок), вновь создаваемый процесс называется порожденным (процесс-потомок).
Процесс-потомок всегда имеет более высокий приоритет, чем процесс-предок, так как приоритет процесса является самым высоким в момент порождения и уменьшается по мере нахождения в состоянии выполнения.
Нулевой процесс, возникающий внутри ядра при загрузке системы, является единственным процессом, не создаваемым с помощью функции fork.
EXIT
Завершение выполнения процесса:
void exit(int status);
где status - значение, возвращаемое функцией родительскому процессу. Процессы могут вызывать функцию exit как в явном, так и в неявном виде (по окончании выполнения программы функция exit вызывается автоматически с параметром 0). Также ядро может вызывать функцию exit по своей инициативе, если процесс не принял посланный ему сигнал. В этом случае значение параметра status равно номеру сигнала. Выполнение вызова exit приводит к �прекращению существования� процесса, освобождению ресурсов и ликвидации контекста.
WAIT
Ожидание завершения выполнения процесса-потомка:
int wait(int *stat);
pid = wait(stat_addr);
где pid - значение кода идентификации (PID) завершившегося потомка, stat_addr - адрес переменной целого типа, в которую будет помещено возвращаемое функцией exit значение.
С помощью этой функции процесс синхронизирует продолжение своего выполнения с моментом завершения потомка. Ядро ведет поиск потомков процесса, прекративших существование, и в случае их отсутствия возвращает ошибку.
Если потомок, прекративший существование, обнаружен, ядро передает его код идентификации и значение, возвращаемое через параметр функции exit, процессу, вызвавшему функцию wait. Таким образом, через параметр функции exit (status) завершающийся процесс может передавать различные значения, в закодированном виде содержащие информацию о причине завершения процесса, однако на практике этот параметр используется по назначению довольно редко.
Если процесс, выполняющий функцию wait, имеет потомков, продолжающих существование, он приостанавливается до получения ожидаемого сигнала. Ядро не возобновляет по своей инициативе процесс, приостановившийся с помощью функции wait: такой процесс может возобновиться только в случае получения сигнала о �гибели потомка�.
SLEEP
Приостанов работы процесса на определенное время:
void sleep(unsigned seconds);
где seconds - количество секунд, на которое требуется приостановить работу процесса.
Сначала ядро повышает приоритет работы процесса так, чтобы заблокировать все прерывания, которые могли бы (путем создания конкуренции) помешать работе с очередями приостановленных процессов, и запоминает старый приоритет, чтобы восстановить его, когда выполнение процесса будет возобновлено. Процесс получает пометку �приостановленного�, адрес приостанова и приоритет запоминаются в таблице процессов, а процесс помещается в хеш-очередь приостановленных процессов. В простейшем случае (когда приостанов не допускает прерываний) процесс выполняет переключение контекста и благополучно �засыпает�. Когда приостановленный процесс �пробуждается�, ядро начинает планировать его запуск: процесс возвращает сохраненный в алгоритме sleep контекст, восстанавливает старый приоритет работы процесса (который был у него до начала выполнения алгоритма) и возвращает управление ядру. Таким образом, нельзя гарантировать, что по истечении заданного времени приостановленный процесс сразу возобновит свою работу: он может быть выгружен на время приостанова и тогда требуется его подкачка в память; в это время на выполнении может находится процесс с более высоким приоритетом или процесс, не допускающий прерываний (например, находящийся в критическом интервале) и т.д.
Параметр seconds устанавливает минимальный интервал, в течение которого процесс будет приостановлен, а реальное время приостанова в любом случае будет несколько больше, хотя бы за счет времени, необходимого для переключения процессов.
EXEC
Запуск программы.
Системный вызов exec осуществляет несколько библиотечных функций - execl, execv, execle и др. Приведем формат одной из них:
int execv(char *path, char *argv[]);
res = execv(path, argv);
где path - имя исполняемого файла, argv - указатель на массив параметров, которые передаются вызываемой программе. Этот массив аналогичен параметру argv командной строки функции main. Список argv должен содержать минимум два параметра: первый - имя программы, подлежащей выполнению (отображается в argv[0] функции main новой программы), второй - NULL (завершающий список аргументов).
Системный вызов exec дает возможность процессу запускать другую программу, при этом соответствующий этой программе исполняемый файл будет располагаться в пространстве памяти процесса. Содержимое пользовательского контекста после вызова функции становится недоступным, за исключением передаваемых функции параметров, которые переписываются ядром из старого адресного пространства в новое.
Вызов exec возвращает 0 при успешном завершении и -1 при аварийном. В последнем случае управление возвращается в вызывающую программу.
В качестве примера использования этого вызова можно привести работу командного интерпретатора shell: при выполнении команды он сначала порождает свою копию с помощью вызова fork, а затем запускает соответствующую указанной команде программу системным вызовом exec.
3.2.2. Системные вызовы для работы с сигналами
Рассмотрим наиболее часто используемые системные вызовы при работе с сигналами в ОС UNIX, описанные в библиотеке <signal.h>.
KILL
Посылка всем или некоторым процессам любого сигнала:
int kill(pid, sig);
где sig - номер сигнала, pid - идентификатор процесса, определяющий группу родственных процессов, которым будет послан данный сигнал:
- - если pid - положительное целое число, ядро посылает сигнал процессу с идентификатором pid.
- - если значение pid равно 0, сигнал посылается всем процессам, входящим в одну группу с процессом, вызвавшим функцию kill.
- - если значение pid равно -1, сигнал посылается всем процессам, у которых реальный код идентификации пользователя совпадает с тем, под которым исполняется процесс, вызвавший функцию kill. Если процесс, пославший сигнал, исполняется под кодом идентификации суперпользователя, сигнал рассылается всем процессам, кроме процессов с идентификаторами 0 и 1.
- - если pid - отрицательное целое число, но не -1, сигнал посылается всем процессам, входящим в группу с номером, равным абсолютному значению pid.
Вызов kill возвращает 0 при успешном завершении и -1 при аварийном (например, спецификация несуществующего в ОС UNIX сигнала или несуществующего процесса).
Во всех случаях, если процесс, пославший сигнал, исполняется под кодом идентификации пользователя, не являющегося суперпользователем, или если коды идентификации пользователя (реальный и исполнительный) у этого процесса не совпадают с соответствующими кодами процесса, принимающего сигнал, kill завершается неудачно.
Посылка сигнала может сопровождать возникновение любого события. Сигналы SIGUSR1, SIGUSR2 и SIGKILL могут быть посланы только с помощью системного вызова kill.
SIGNAL
Позволяет процессу самому определить свою реакцию на получение того или иного сигнала:
#include <signal.h>
void (*signal(signum, void (*handler)(int)))(int)
int signum;
void handler(int);
После определения реакции на сигнал signal при получении процессом этого сигнала будет автоматически вызываться функция handler(), которая, естественно, должна быть описана или объявлена прежде, чем будет осуществлен системный вызов signal.
При многократной обработке одного и того же сигнала, процесс должен каждый раз осуществлять системный вызов signal для установления требуемой реакции на данный сигнал. Использование констант SIG_DFL и SIG_IGN позволяет упростить реализацию двух часто встречающихся реакций процесса на сигнал:
signal(SIGINT,SIG_IGN) игнорирование сигнала;
signal(SIGINT,SIG_DFL) восстановление стандартной реакции на сигнал.
Аргументом функции-обработчика является целое число – номер обрабатываемого сигнала. Значение его устанавливается ядром.
PAUSE
Приостанавливает функционирование процесса до получения им некоторого сигнала:
void pause();
Этот системный вызов не имеет параметров. Работа процесса возобновляется после получения им любого сигнала, кроме тех, которые игнорируются этим процессом.
ALARM
Посылка процессу сигнала побудки SIGALARM:
unsigned alarm(unsigned secs);
Этим системным вызовом процесс информирует ядро ОС о том, что ядро должно послать этому процессу сигнал побудки через secs секунд. Вызов alarm возвращает число секунд, заданное при предыдущем осуществлении этого системного вызова.
Если secs равно 0, то специфицированная ранее посылка процессу сигнала SIGALARM будет отменена.
Пример 1. Порождение процессов.
Нижеприведенная программа в результате выполнения породит три процесса (процесс-предок 1 и процессы-потомки 2 и 3).
#include <sys/types.h>
#include <fcntl.h>
#include <stdio.h>
void main(void)
{
int pid2, pid3, st; /* process 1 */
printf(�Process 1, pid = %d:\n�, getpid());
pid2 = fork();
if (pid2 == 0) /* process 2 */
{
����������������������� printf(�Process 2, pid = %d:\n�, getpid());
����������������������� pid3 = fork();
����������������������� if (pid3 == 0) /* process 3 */
����������������������� {��������� printf(�Process 3, pid = %d:\n�, getpid());
���������������������������������� sleep(2);
���������������������������������� printf(�Process 3: end\n�);
����������������������� } /* process 2 */
����������������������� if (pid3 < 0) printf(�Cann't create process 3: error %d\n�, pid3);
����������������������� wait(&st);
����������������������� printf(�Process 2: end\n�);
}
else /* process 1 */
{��������� if (pid2 < 0) printf(�Cann't create process 2: error %d\n�, pid2);
����������������������� wait(&st);
����������������������� printf(�Process 1: end\n�);
}
exit(0);
}
В соответствии с программой первоначально будет создан процесс1 (как потомок интерпретатора shell), он сообщит о начале своей работы и породит процесс2. После этого работа процесса1 приостановится и начнет выполняться процесс2 как более приоритетный. Он также сообщит о начале своей работы и породит процесс3. Далее начнет выполняться процесс3, он сообщит о начале работы и �заснет�. После этого возобновит свое выполнение либо процесс1, либо процесс2 в зависимости от величин приоритетов и от того, насколько процессор загружен другими процессами. Так как ни один из процессов не выполняет никакой работы, они, вероятнее всего, успеют завершится до возобновления процесса3, который в этом случае завершится последним.
Пример 2. Синхронизация работы процессов.
Приведенная в данном разделе программа в результате выполнения породит три процесса (процесс-предок 0 и процессы-потомки 1 и 2). Процессы 1 и 2 будут обмениваться сигналами и выдавать соответствующие сообщения на экран, а процесс 0 через определенное количество секунд отправит процессам 1 и 2 сигнал завершения и сам прекратит свое функционирование.
#include <sys/types.h>
#include <fcntl.h>
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
#define TIMEOUT 10
extern int f1(int), f2(int), f3(int);
int pid0, pid1, pid2;
void main(void)
{��������� setpgrp();
pid0 = getpid();
pid1 = fork();
if (pid1 == 0) /* process 1 */
{��������� signal(SIGUSR1, f1);
����������������������� pid1 = getpid();
����������������������� pid2 = fork();
����������������������� if (pid2 < 0 ) puts(�Fork error�);
����������������������� if (pid2 > 0) for(;;);
����������������������� else /* process 2 */
����������������������� {��������� signal(SIGUSR2, f2);
���������������������������������� pid2 = getpid();
���������������������������������� kill(pid1,SIGUSR1);
���������������������������������� for (;;);
����������������������� }
}
else /* process 0 */
{��������� signal(SIGALRM, f3);
����������������������� alarm(TIMEOUT);
����������������������� pause();
}
exit(0);
}
int f1(int signum)
{��������� signal(SIGUSR1, f1);
printf(�Process 1 (%d) has got a signal from process 2 (%d)\n�,pid1,pid2);
sleep(1);
kill(pid2, SIGUSR2);
return 0;
}
int f2(int signum)
{��������� signal(SIGUSR2, f2);
printf(�Process 2 (%d) has got a signal from process 1 (%d)\n�,pid2,pid1);
sleep(1);
kill(pid1, SIGUSR1);
return 0;
}
int f3(int signum)
{��������� printf(�End of job - %d\n�, pid0);
kill(0, SIGKILL);
return 0;
}
4. ИСПОЛЬЗОВАНИЕ СЕМАФОРОВ И РАЗДЕЛЯЕМОЙ ПАМЯТИ
4.1.1. Взаимодействие процессов в версии V системы UNIX
Пакет IPC (Interprocess communication) в версии V системы UNIX включает в себя три механизма. Механизм сообщений дает процессам возможность посылать другим процессам потоки сформатированных данных, механизм разделения памяти позволяет процессам совместно использовать отдельные части виртуального адресного пространства, а семафоры - синхронизировать свое выполнение с выполнением параллельных процессов. Несмотря на то, что они реализуются в виде отдельных блоков, им присущи общие свойства.
� � С каждым механизмом связана таблица, в записях которой описываются все его детали.
� � В каждой записи содержится числовой ключ (key), который представляет собой идентификатор записи, выбранный пользователем.
� � В каждом механизме имеется системная функция типа �get�, используемая для создания новой или поиска существующей записи; параметрами функции являются идентификатор записи и различные флаги (flag). Ядро ведет поиск записи по ее идентификатору в соответствующей таблице. Процессы могут с помощью флага IPC_PRIVATE гарантировать получение еще неиспользуемой записи. С помощью флага IPC_CREAT они могут создать новую запись, если записи с указанным идентификатором нет, а если еще к тому же установить флаг IPC_EXCL, можно получить уведомление об ошибке в том случае, если запись с таким идентификатором существует. Функция возвращает некий выбранный ядром дескриптор, предназначенный для последующего использования в других системных функциях, таким образом, она работает аналогично системным функциям creat и open.
� � В каждом механизме ядро использует следующую формулу для поиска по дескриптору указателя на запись в таблице структур данных: �указатель = <значение дескриптора> mod <число записей в таблице>�. Если, например, таблица записей разделяемой памяти состоит из 100 записей, дескрипторы, связанные с записью номер 1, имеют значения, равные 1, 101, 201 и т.д. Когда процесс удаляет запись, ядро увеличивает значение связанного с ней дескриптора на число записей в таблице: полученный дескриптор станет новым дескриптором этой записи, когда к ней вновь будет произведено обращение при помощи функции типа �get�. Процессы, которые будут пытаться обратиться к записи по ее старому дескриптору, потерпят неудачу. Обратимся вновь к предыдущему примеру. Если с записью 1 связан дескриптор, имеющий значение 201, при его удалении ядро назначит записи новый дескриптор, имеющий значение 301. Процессы, пытающиеся обратиться к дескриптору 201, получат ошибку, поскольку этого дескриптора больше нет. В конечном итоге ядро произведет перенумерацию дескрипторов, но пока это произойдет, может пройти значительный промежуток времени.
� � Каждая запись имеет некую структуру данных, описывающую права доступа к ней и включающую в себя пользовательский и групповой коды идентификации, которые имеет процесс, создавший запись, а также пользовательский и групповой коды идентификации, установленные системной функцией типа �control� (об этом ниже), и двоичные коды разрешений чтения-записи-исполнения для владельца, группы и прочих пользователей, по аналогии с установкой прав доступа к файлам.
� � В каждой записи имеется другая информация, описывающая состояние записи, в частности, идентификатор последнего из процессов, внесших изменения в запись (посылка сообщения, прием сообщения, подключение разделяемой памяти и т.д.), и время последнего обращения или корректировки.
� � В каждом механизме имеется системная функция типа �control�, запрашивающая информацию о состоянии записи, изменяющая эту информацию или удаляющая запись из системы. Когда процесс запрашивает информацию о состоянии записи, ядро проверяет, имеет ли процесс разрешение на чтение записи, после чего копирует данные из записи таблицы по адресу, указанному пользователем. При установке значений принадлежащих записи параметров ядро проверяет, совпадают ли между собой пользовательский код идентификации процесса и идентификатор пользователя (или создателя), указанный в записи, не запущен ли процесс под управлением суперпользователя; одного разрешения на запись недостаточно для установки параметров. Ядро копирует сообщенную пользователем информацию в запись таблицы, устанавливая значения пользовательского и группового кодов идентификации, режимы доступа и другие параметры (в зависимости от типа механизма). Ядро не изменяет значения полей, описывающих пользовательский и групповой коды идентификации создателя записи, поэтому пользователь, создавший запись, сохраняет управляющие права на нее. Пользователь может удалить запись, либо если он является суперпользователем, либо если идентификатор процесса совпадает с любым из идентификаторов, указанных в структуре записи. Ядро увеличивает номер дескриптора, чтобы при следующем назначении записи ей был присвоен новый дескриптор. Следовательно, как уже ранее говорилось, если процесс попытается обратиться к записи по старому дескриптору, вызванная им функция получит отказ. Для использования механизмов IPC необходимо подключить кпрограмме файл <sys/ipc.h>.
.1.2. Использование разделяемой памяти
Процессы могут взаимодействовать друг с другом непосредственно путем разделения (совместного использования) участков виртуального адресного пространства и обмена данными через разделяемую память. Процессы ведут чтение и запись данных в области разделяемой памяти, используя для этого те же самые машинные команды, что и при работе с обычной памятью.
После создания области разделяемой памяти и присоединения ее к виртуальному адресному пространству процесса эта область становится доступна так же, как любой участок виртуальной памяти; для доступа к находящимся в ней данным не нужны обращения к каким-то дополнительным системным функциям.
Механизм разделения памяти имеет много общего с механизмом функционирования файловой системы. Но в отличие от файлов ядро не располагает сведениями о том, какие процессы могут использовать механизм разделяемой памяти, а, следовательно, оно не может автоматически очищать неиспользуемые структуры механизма взаимодействия процессов, поскольку ядру неизвестно, какие из этих структур больше не нужны. Таким образом, завершившиеся вследствие возникновения ошибки процессы могут оставить после себя ненужные и неиспользуемые структуры, перегружающие и засоряющие систему. Для того, чтобы избежать подобных ситуаций, необходимо с большой осторожностью пользоваться этим механизмом и обязательно удалять разделяемую память после использования.
В настоящее время все большее значение придается крупным вычислительным системам, таким как многопроцессорные вычислительные комплексы и сети ЭВМ. Основным средством увеличения мощностей вычислительных машин является повышение в них уровня параллелизма. Очевидно, что параллельность в аппаратуре отражается и на программном обеспечении. В связи с этим значительно возрастает интерес к параллельным процессам и проблемам их синхронизации.
На сегодняшний день предложено большое количество различных систем синхронизации процессов. К ним относятся:
- - блокировка памяти;
- - семафоры;
- - критические области;
- - условные критические области;
- - мониторы;
- - исключающие области и т.д..
Один из способов синхронизации параллельных процессов - семафоры Дейкстры, реализованные в ОС UNIX.
Определим понятие процесса как задания, выполняемого в операционной системе. Поскольку задания в многопользовательской системе должны выполняться независимо и могут выполняться параллельно, то и представляющие их процессы должны быть независимыми и параллельно выполняемыми.
Процессам для работы часто требуются различные устройства и вспомогательные программы, которые можно назвать соответственно аппаратными и программными ресурсами. Если мы хотим эффективно использовать эти ресурсы, то те и другие должны совместно использоваться несколькими процессами. Такие совместно используемые ресурсы называются разделяемыми ресурсами.
Если по условиям работы требуется, чтобы разделяемые ресурсы одномоментно были доступны только одному процессу, то такие ресурсы называются критическими.
Под независимостью процессов понимается, что кроме (достаточно редких) моментов явной связи, процессы рассматриваются как совершенно независимые друг от друга. Но на самом деле они не являются вполне независимыми, так как они могут использовать в процессе своего выполнения одни и те же ресурсы. Процесс упорядочения общения между конкурирующими процессами называется синхронизацией. Синхронизация задается с помощью синхронизирующих правил. Реализация таких правил осуществляется с помощью средств синхронизации.
Элементарные приемы синхронизации, такие как использование общих переменных, имеют ряд недостатков, которые иногда приводят к невозможности получения правильных решений. Поэтому возникла необходимость в создании специальных синхронизирующих примитивов.
Такие примитивы под названием P и V операции были предложены Дейкстрой в 1968 году. Эти операции могут выполняться только над специальными переменными, называемыми семафорами или семафорными переменными. Семафоры являются целыми величинами и первоначально были определены как принимающие только неотрицательные значения. Кроме того, если их использовать для решения задач взаимного исключения, то область их значений может быть ограничена лишь �0� или �1�. Однако в дальнейшем была показана важная область применения семафоров, принимающих любые целые положительные значения. Такие семафоры получили название �общих семафоров� в отличие от �двоичных семафоров�, используемых в задачах взаимного исключения. P и V операции являются единственными операциями, выполняемыми над семафорами. Иногда они называются семафорными операциями.
Дадим определение P и V операций в том виде, в котором они были предложены Дейкстрой.
V - операция (V(S)):
операция с одним аргументом, который должен быть семафором.
Эта операция увеличивает значение аргумента на 1.
P - операция (P(S)):
операция с одним аргументом, который должен быть семафором. Ее назначение - уменьшить величину аргумента на 1, если только результирующее значение не становится отрицательным.
Завершение P-операции, т.е. решение о том, что настоящий момент является подходящим для выполнения уменьшения и последующее собственно уменьшение значения аргумента, должно рассматриваться как неделимая операция.
Эти определения справедливы как для общих, так для двоичных семафоров.
Системные вызовы для работы с семафорами содержатся в пакете IPC (подключаемый файл описаний - <sys/ipc.h>). Эти вызовы обеспечивают синхронизацию выполнения параллельных процессов, производя набор действий только над группой семафоров (средствами низкого уровня).
UNIX поддерживает числовые семафоры (как расширение двоичных семафоров). Семафоры UNIX носят не обязательный, а уведомительный характер. Это означает, что связь между семафором и тем ресурсом (ресурсами), доступ к которому разграничивает данный семафор, является чисто логической. Если при обращении к этому ресурсу процесс не запросит доступ к нему через семафор, никто не помешает процессу получить этот доступ (при наличии соответствующих прав). Таким образом, процессы должны заранее договариваться об использовании семафоров.
Каждый семафор в системе UNIX представляет собой набор значений (вектор семафоров). Связанные с семафорами системные функции являются обобщением операций P и V семафоров Дейкстры, в них допускается одновременное выполнение нескольких операций (над семафорами, принадлежащими одному вектору, так называемые векторные операции). Ядро выполняет операции комплексно; ни один из посторонних процессов не сможет переустанавливать значения семафоров, пока все операции не будут выполнены. Если ядро по каким-либо причинам не может выполнить все операции, оно не выполняет ни одной; процесс приостанавливает свою работу до тех пор, пока эта возможность не будет предоставлена. (Подробнее о порядке операций над семафорами см. п. 2. �Системные вызовы�).
Семафор в System V состоит из следующих элементов:
- - значение семафора,
- - идентификатор последнего из процессов, работавших с семафором,
- - количество процессов, ожидающих увеличения значения семафора,
- - количество процессов, ожидающих момента, когда значение семафора станет равным 0.
Для создания набора семафоров и получения доступа к ним используется системная функция semget, для выполнения различных управляющих операций над набором - функция semctl, для работы со значениями семафоров - функция semop.
Механизм функционирования файловой системы и механизмы взаимодействия процессов имеют ряд общих черт. Системные функции типа �get� похожи на функции creat и open, функции типа �control� (ctl) предоставляют возможность удалять дескрипторы из системы, чем похожи на функцию unlink. Тем не менее, в механизмах взаимодействия процессов отсутствуют операции, аналогичные операциям, выполняемым системной функцией close. Следовательно, ядро не располагает сведениями о том, какие процессы используют механизм IPC, и, действительно, процессы могут прибегать к услугам этого механизма, если правильно �угадывают� соответствующий идентификатор и если у них имеются необходимые права доступа, даже если они не выполнили предварительно функцию типа �get�.
Выше уже говорилось, что ядро не может автоматически очищать неиспользуемые структуры механизма взаимодействия процессов, поскольку ядру неизвестно, какие из этих структур больше не нужны. Таким образом, завершившиеся вследствие возникновения ошибки процессы могут оставить после себя ненужные и неиспользуемые структуры, перегружающие и засоряющие систему. Несмотря на то, что в структурах механизма взаимодействия после завершения существования процесса ядро может сохранить информацию о состоянии и данные, лучше для этих целей использовать файлы.
Вместо традиционных, получивших широкое распространение файлов механизмы взаимодействия процессов используют новое пространство имен, состоящее из ключей (keys). Расширить семантику ключей на всю сеть довольно трудно, поскольку на разных машинах ключи могут описывать различные объекты. Короче говоря, ключи в основном предназначены для использования в одномашинных системах. Имена файлов в большей степени подходят для распределенных систем. Использование ключей вместо имен файлов также свидетельствует о том, что средства взаимодействия процессов являются �вещью в себе�, полезной в специальных приложениях, но не имеющей тех возможностей, которыми обладают, например, каналы и файлы.
Большая часть функциональных возможностей, предоставляемых данными средствами, может быть реализована с помощью других системных средств, поэтому включать их в состав ядра вряд ли следовало бы. Тем не менее, их использование в составе пакетов прикладных программ тесного взаимодействия дает лучшие результаты по сравнению со стандартными файловыми средствами.
4.2.1. Системные вызовы для работы с разделяемой памятью
Системные вызовы для работы с разделяемой памятью в ОС UNIX
описаны в библиотеке <sys/shm.h>.
Функция shmget создает новую область разделяемой памяти или возвращает адрес уже существующей области, функция shmat логически присоединяет область к виртуальному адресному пространству процесса, функция shmdt отсоединяет ее, а функция shmctl позволяет получать информацию о состоянии разделяемой памяти и производить над ней операции.
SHMGET
Создание области разделяемой памяти или получение номера дескриптора существующей области:
int shmget(key_t key, int size, int flag);
id = shmget(key, size, flag);
где id - идентификатор области разделяемой памяти, key - номер области, size - объем области в байтах, flag - параметры создания и права доступа.
Ядро использует key для ведения поиска в таблице разделяемой памяти: если подходящая запись обнаружена и если разрешение на доступ имеется, ядро возвращает вызывающему процессу указанный в записи дескриптор. Если запись не найдена и пользователь установил флаг IPC_CREAT, указывающий на необходимость создания новой области, ядро проверяет нахождение размера области в установленных системой пределах и выделяет область.
Ядро записывает установки прав доступа, размер области и указатель на соответствующую запись таблицы областей в таблицу разделяемой памяти (Рис.4.1) и устанавливает флаг, свидетельствующий о том, что с областью не связана отдельная память.
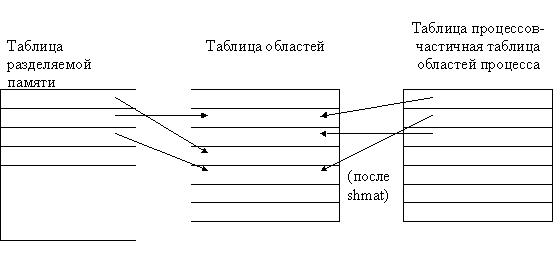
Рисунок 4.1. Структуры данных, используемые при разделении памяти.
Области выделяется память (таблицы страниц и т.п.) только тогда, когда процесс присоединяет область к своему адресному пространству. Ядро устанавливает также флаг, говорящий о том, что по завершении последнего связанного с областью процесса область не должна освобождаться. Таким образом, данные в разделяемой памяти остаются в сохранности, даже если она не принадлежит ни одному из процессов (как часть виртуального адресного пространства последнего).
SHMAT
Присоединяет область разделяемой памяти к виртуальному адресному пространству процесса:
void *shmat(int id, void *addr, int flag);
virtaddr = shmat(id, addr, flag);
Значение id, возвращаемое функцией shmget, идентифицирует область разделяемой памяти, addr является виртуальным адресом, по которому пользователь хочет подключить область, а с помощью флагов (flag) можно указать, предназначена ли область только для чтения и нужно ли ядру округлять значение указанного пользователем адреса. Возвращаемое функцией значение, virtaddr, представляет собой виртуальный адрес, по которому ядро произвело подключение области и который не всегда совпадает с адресом, указанным пользователем. В начале выполнения системной функции shmat ядро проверяет наличие у процесса необходимых прав доступа к области. Оно исследует указанный пользователем адрес; если он равен 0, ядро выбирает виртуальный адрес по своему усмотрению. Область разделяемой памяти не должна пересекаться в виртуальном адресном пространстве процесса с другими областями; следовательно, ее выбор должен производиться разумно и осторожно. Так, например, процесс может увеличить размер принадлежащей ему области данных с помощью системного вызова brk, и новая область данных будет содержать адреса, смежные с прежней областью; поэтому ядру не следует присоединять область разделяемой памяти слишком близко к области данных процесса. Так же не следует размещать область разделяемой памяти вблизи от вершины стека, чтобы стек при своем последующем увеличении не залезал за ее пределы. Если, например, стек растет в направлении увеличения адресов, лучше всего разместить область разделяемой памяти непосредственно перед началом области стека. Ядро проверяет возможность размещения области разделяемой памяти в адресном пространстве процесса и присоединяет ее, если это возможно.
Если вызывающий процесс является первым процессом, который присоединяет область, ядро выделяет для области все необходимые таблицы, записывает время присоединения в соответствующее поле таблицы разделяемой памяти и возвращает процессу виртуальный адрес, по которому область была им подключена фактически.
SHMDT
Отсоединение области разделяемой памяти от виртуального адресного пространства процесса:
int shmdt(void *addr);
где addr - виртуальный адрес, возвращенный функцией shmat. Процесс использует виртуальный адрес разделяемой памяти, а не ее идентификатор, поскольку этот идентификатор может быть удален из системы. Ядро производит поиск области по указанному адресу и отсоединяет ее от адресного пространства процесса. Поскольку в таблицах областей отсутствуют обратные указатели на таблицу разделяемой памяти, ядру приходится просматривать таблицу разделяемой памяти в поисках записи, указывающей на данную область, и записывать в соответствующее поле время последнего отключения области.
Отсоединение области от виртуального адресного пространства процесса не означает удаления области: сведения о ней остаются в таблице разделяемой памяти, данные, содержащиеся в ней, также сохраняются. Очищения таблиц и освобождения памяти можно добиться с помощью соответствующего флага в операции shmctl.
SHMCTL
Получение информации о состоянии области разделяемой памяти и установка параметров для нее:
int shmctl(int id, int cmd, struct shmid_ds *buf);
Значение id (возвращаемое функцией shmget) идентифицирует запись таблицы разделяемой памяти, cmd определяет тип операции, а buf является адресом пользовательской структуры, хранящей информацию о состоянии области. Типы операций описываются списком определений в файле �sys/ipc.h�:
#define IPC_RMID�� 10������� /* удалить идентификатор (область) */
#define IPC_SET����� 11������� /* установить параметры */
#define IPC_STAT��� 12������� /* получить параметры */
С помощью команды (флага) IPC_RMID можно удалить область id. Удаляя область разделяемой памяти, ядро освобождает соответствующую ей запись в таблице разделяемой памяти и просматривает таблицу областей: если область не была присоединена ни к одному из процессов, ядро освобождает запись таблицы и все выделенные области ресурсы. Если же область по-прежнему подключена к каким-то процессам (значение счетчика ссылок на нее больше 0), ядро только сбрасывает флаг, говорящий о том, что по завершении последнего связанного с нею процесса область не должна освобождаться. Процессы, уже использующие область разделяемой памяти, продолжают работать с ней, новые же процессы не могут присоединить ее. Когда все процессы отключат область, ядро освободит ее. Это похоже на то, как в файловой системе после разрыва связи с файлом процесс может вновь открыть его и продолжать с ним работу.
4.2.2. Системные вызовы для работы с семафорами
Системные вызовы для работы с семафорами в ОС UNIX описаны в
библиотеке <sys/sem.h>.
SEMGET
Создание набора семафоров и получение доступа к ним:
int semget(key_t key, int count, int semflg);
semid = semget(key, count, semflg);
где key - номер семафора, count - количество семафоров, semflg - параметры создания и права доступа. Ядро использует key для ведения поиска в таблице семафоров: если подходящая запись обнаружена и разрешение на доступ имеется, ядро возвращает вызывающему процессу указанный в записи дескриптор. Если запись не найдена, а пользователь установил флаг IPC_CREAT - создание нового семафора, - ядро проверяет возможность его создания и выделяет запись в таблице семафоров. Запись указывает на массив семафоров и содержит счетчик count (Рис.4.2). В записи также хранится количество семафоров в массиве, время последнего выполнения функций semop и semctl.
Рисунок 4.2. Структуры данных, используемые в работе над семафорами.
SEMOP
Установка или проверка значения семафора:
int semop(int semid, struct sembuf *oplist, unsigned nsops);
где semid - дескриптор, возвращаемый функцией semget, oplist - указатель на список операций, nsops - размер списка. Возвращаемое функцией значение является прежним значением семафора, над которым производилась операция. Каждый элемент списка операций имеет следующий формат (определение структуры sembuf в файле sys/sem.h):
struct sembuf
{��������� unsigned short sem_num;
short sem_op;
short sem_flg;
}
где shortsem_num - номер семафора, идентифицирующий элемент массива семафоров, над которым выполняется операция; sem_op - код операции; sem_fl – флаги операции. Ядро считывает список операций oplist из адресного пространства задачи и проверяет корректность номеров семафоров, а также наличие у процесса необходимых разрешений на чтение и корректировку семафоров. Если таких разрешений не имеется, системная функция завершается неудачно (res = -1). Если ядру приходится приостанавливать свою работу при обращении к списку операций, оно возвращает семафорам их прежние значения и находится в состоянии приостанова до наступления ожидаемого события, после чего системная функция запускается вновь. Поскольку ядро хранит коды операций над семафорами в глобальном списке, оно вновь считывает этот список из пространства задачи, когда перезапускает системную функцию. Таким образом, операции выполняются комплексно - или все за один сеанс, или ни одной.
Установка флага IPC_NOWAIT в функции semop имеет следующий смысл: если ядро попадает в такую ситуацию, когда процесс должен приостановить свое выполнение в ожидании увеличения значения семафора выше определенного уровня или, наоборот, снижения этого значения до 0, и если при этом флаг IPC_NOWAIT установлен, ядро выходит из функции с извещением об ошибке. (Таким образом, если не приостанавливать процесс в случае невозможности выполнения отдельной операции, можно реализовать условный тип семафора). Флаг SEM_UNDO позволяет избежать блокирования семафора процессом, который закончил свою работу прежде, чем освободил захваченный им семафор. Если процесс установил флаг SEM_UNDO, то при завершении этого процесса ядро даст обратный ход всем операциям, выполненным процессом. Для этого в распоряжении у ядра имеется таблица, в которой каждому процессу отведена отдельная запись. Запись содержит указатель на группу структур восстановления, по одной структуре на каждый используемый процессом семафор (Рис.4.3).
Каждая структура восстановления состоит из трех элементов - идентификатора семафора, его порядкового номера в наборе и установочного значения. Ядро выделяет структуры восстановления динамически, во время первого выполнения системной функции semop с установленным флагом SEM_UNDO. При последующих обращениях к функции с тем же флагом ядро просматривает структуры восстановления для процесса в поисках структуры с тем же самым идентификатором и порядковым номером семафора, что и в вызове функции. Если структура обнаружена, ядро вычитает значение произведенной над семафором операции из установочного значения. Таким образом, в структуре восстановления хранится результат вычитания суммы значений всех операций, произведенных над семафором, для которого установлен флаг SEM_UNDO.
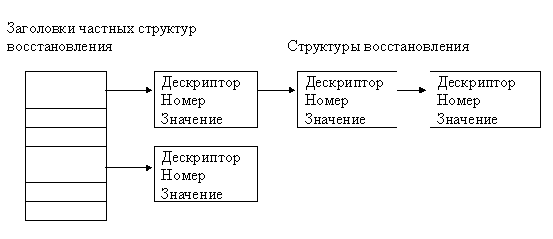
Рисунок 4.3. Структуры восстановления семафоров
Если соответствующей структуры нет, ядро создает ее, сортируя при этом список структур по идентификаторам и номерам семафоров. Если установочное значение становится равным 0, ядро удаляет структуру из списка. Когда процесс завершается, ядро вызывает специальную процедуру, которая просматривает все связанные с процессом структуры восстановления и выполняет над указанным семафором все обусловленные действия.
Ядро меняет значение семафора в зависимости от кода операции, указанного в вызове функции semop. Если код операции имеет положительное значение, ядро увеличивает значение семафора и выводит из состояния приостанова все процессы, ожидающие наступления этого события. Если код операции равен 0, ядро проверяет значение семафора: если оно равно 0, ядро переходит к выполнению других операций; в противном случае ядро увеличивает число приостановленных процессов, ожидающих, когда значение семафора станет нулевым, и �засыпает�.
Если код операции отрицателен и если его абсолютное значение не превышает значение семафора, ядро прибавляет код операции (отрицательное число) к значению семафора. Если результат равен 0, ядро выводит из состояния приостанова все процессы, ожидающие обнуления значения семафора. Если результат меньше абсолютного значения кода операции, ядро приостанавливает процесс до тех пор, пока значение семафора не увеличится. Если процесс приостанавливается посреди операции, он имеет приоритет, допускающий прерывания; следовательно, получив сигнал, он выходит из этого состояния.
SEMCTL
Выполнение управляющих операций над набором семафоров:
int semctl(int semid, int semnum, int cmd, union semun arg);
Параметр arg объявлен как объединение типов данных:
union semunion
{��������� int val; // используется только для SETVAL
struct semid_ds *semstat; // для IPC_STAT и IPC_SET
unsigned short *array;
} arg;
Ядро интерпретирует параметр arg в зависимости от значения параметра cmd, который может принимать следующие значения:
GETVAL - вернуть значение того семафора, на который указывает параметр num.
SETVAL - установить значение семафора, на который указывает параметр num, равным значению arg.val.
GETPID - вернуть идентификатор процесса, выполнявшего последним функцию semop по отношению к тому семафору, на который указывает параметр semnum.
GETNCNT - вернуть число процессов, ожидающих того момента, когда значение семафора станет положительным.
GETZCNT - вернуть число процессов, ожидающих того момента, когда значение семафора станет нулевым.
GETALL - вернуть значения всех семафоров в массиве arg.array.
SETALL - установить значения всех семафоров в соответствии с содержимым массива arg.array.
IPC_STAT - считать структуру заголовка семафора с идентификатором id в буфер arg.buf. Аргумент semnum игнорируется.
IPC_SET – запись структуры семафора из буфера arg.buf.
IPC_RMID - удалить семафоры, связанные с идентификатором id, из системы.
Если указана команда удаления IPC_RMID, ядро ведет поиск всех процессов, содержащих структуры восстановления для данного семафора, и удаляет соответствующие структуры из системы. Затем ядро инициализирует используемые семафором структуры данных и выводит из состояния приостанова все процессы, ожидающие наступления некоторого связанного с семафором события: когда процессы возобновляют свое выполнение, они обнаруживают, что идентификатор семафора больше не является корректным, и возвращают вызывающей программе ошибку. Если возвращаемое функцией число равно 0, то функция завершилась успешно, иначе (возвращаемое значение равно -1) произошла ошибка. Код ошибки хранится в переменной errno.
4.3. ПРИМЕРЫ ПРОГРАММ РАБОТЫ С СЕМАФОРАМИ
Пример 1. Запись в область разделяемой памяти и чтение из нее.
Первая из программ описывает процесс, в котором создается область разделяемой памяти размером 128 Кбайт и производится запись и считывание данных из этой области.
В соответствии со второй программой другой процесс присоединяет ту же область (он получает только 64 Кбайта, таким образом, каждый процесс может использовать разный объем области разделяемой памяти); он ждет момента, когда первый процесс запишет в первое принадлежащее области слово любое отличное от нуля значение, и затем принимается считывать данные из области.
Первый процесс делает �паузу� (pause), предоставляя второму процессу возможность выполнения; когда первый процесс принимает сигнал, он удаляет область разделяемой памяти из системы.
/*
Запись в разделяемую память и чтение из нее
*/
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#define���������������������� SHMKEY ���� 5
#define���������������������� K�������������������� 1024
int shmid;
main()
{
int i, *pint;
char *addr;
extern char *shmat();
extern cleanup();
/* определение реакции на все сигналы */
for (i = 0; i < 20; i++) signal(i, cleanup);
/* создание общедоступной разделяемой области памяти
����������� размером 128*K (или получение ее идентификатора,
����������� если она уже существует) */
shmid = shmget(SHMKEY,128*K,0777�IPC_CREAT);
addr = shmat(shmid,0,0);
pint = (int *) addr;
for (i = 0; i < 256; i++) *pint++ = i;
pint = (int *) addr;
*pint = 256;
pint = (int *) addr;
for (i = 0; i < 256; i++)
����������� printf(�index %d\tvalue %d\n�,i,*pint++);
/* ожидание сигнала */
pause();
}
/* удаление разделяемой памяти */
cleanup()
{
shmctl(shmid,IPC_RMID,0);
exit();
}
/*
Чтение из разделяемой памяти данных, записанных первым
процессом
*/
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#define���������������������� SHMKEY����� 75
#define���������������������� K�������������������� 1024
int shmid;
main()
{��������� int i, *pint;
char *addr;
extern char *shmat();
shmid = shmget(SHMKEY,64*K,0777);
addr = shmat(shmid,0,0);
pint = (int *) addr;
while (*pint == 0); /* ожидание начала записи */
for (i = 0; i < 256, i++) printf(�%d\n�,*pint++);
}
Пример 2. Работа двух параллельных процессов в одном критическом интервале времени.
Для организации работы двух процессов в одном критическом интервале времени необходимо время работы одного процесса сделать недоступным для другого (т.е. второй процесс не может выполняться одновременно с первым). Для этого используем средство синхронизации - семафор. В данном случае нам потребуется один семафор. Опишем его с помощью системной функции ОС UNIX:
lsid = semget(75, 1, 0777 | IPC_CREAT);
где lsid - это идентификатор семафора;75 - ключ пользовательского дескриптора (если он занят, система создаст свой); 1 - количество семафоров в массиве; IPC_CREAT - флаг для создания новой записи в таблице дескрипторов (описан с правами доступа 0777).
Для установки начального значения семафора используем структуру sem. В ней присваиваем значение:
sem.array[0] = 1;
то есть семафор открыт для пользования.
Завершающим шагом является инициализация массива (в данном случае массив состоит из одного элемента):
semctl(lsid,1,SETALL,sem);
где lsid - идентификатор семафора (выделенная строка в дескрипторе); 1 - количество семафоров; SETALL - команда �установить все семафоры�; sem - указатель на структуру.
Устанавливаем флаг SEM_UNDO в структуре sop для работы с функцией semop (значение этого флага не меняется в процессе работы).
Далее в программе организуются два параллельных процесса (потомки �главной� программы) с помощью системной функции fork(). Один процесс-потомок записывает данные в разделяемую память, второй считывает эти данные. При этом процессы-потомки синхронизируют доступ к разделяемой памяти с помощью семафоров.
Функция p() описывается следующим образом:
int p(int sid)
{��������� sop.sem_num = 0; /* номер семафора */
sop.sem_op = -1;
semop(sid, &sop, 1);
}
В структуру sop заносится номер семафора, над которым будет произведена операция и значение самой операции (в данном случае это уменьшение значения на 1). Флаг был установлен заранее, поэтому функция в процессе всегда находится в ожидании свободного семафора. (Функция v() работает аналогично, но sop.sem_op = 1).
Результатом выполнения ниже приведенной программы является список сообщений от процессов, соответствующий последовательности работы процессов.
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/sem.h>
#include <unistd.h>
#include <errno.h>
int shmid, lsid, x;
struct sembuf sop;
union semun
{��������� int val;
struct semid_ds *buf;
ushort *array;
} sem;
int p(int sid)
{��������� sop.sem_num = 1;
sop.sem_op = -1;
semop(sid, &sop, 1);
}
int v(int sid)
{��������� sop.sem_num = 1;
sop.sem_op = 1;
semop(sid, &sop, 1);
}
main()
{��������� int j, i, id, id1, n;
lsid = semget(75, 1, 0777 | IPC_CREAT);
sem.array = (ushort*)malloc(sizeof(ushort));
sem.array[0] = 1;
sop.sem_flg = SEM_UNDO;
semctl(lsid, 1, SETALL, sem);
printf(� n= �);
scanf(�%d�, &n);
id = fork();
if (id == 0) /* первый процесс */
{��������� for(i = 0; i < n; i++)
����������������������� {��������� p(lsid);
���������������������������������� puts(�\n Работает процесс 1�);
���������������������������������� v(lsid);
����������������������� }
exit(0);
}
id1 = fork();
if (id1 == 0) /* второй процесс */
{��������� for (j = 0; j < n; j++)
����������������������� {��������� p(lsid);
���������������������������������� puts(�\n Работает процесс 2�);
���������������������������������� v(lsid);
����������������������� }
����������������������� exit(0);
}
wait(&x);
wait(&x);
exit(0);
}
Пример 3. Векторные операции над семафорами.
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#define SEMKEY 75
int semid;������������������� /* идентификатор семафора */
unsigned int count;���� /* количество семафоров */
struct sembuf psembuf, vsembuf; /* операции типа P и V */
cleanup()
{��������� semctl(semid, 2, IPC_RMID, 0);
exit();
}
main(int argc, char *argv[])
{��������� int i, first, second;
short initarray[2], outarray[2];
if (argc == 1)
{
/* определение реакции на сигналы */
����������������������� for (i = 0; i < 20; i++) signal(i, cleanup);
����������������������� /* создание общедоступного семафора из двух элементов */
����������������������� semid = semget(SEMKEY, 2, 0777�IPC_CREAT);
����������������������� /* инициализация семафоров (оба открыты) */
����������������������� initarray[0] = initarray[1] = 1;
����������������������� semctl(semid, 2, SETALL, initarray);
����������������������� semctl(semid, 2, GETALL, outarray);
����������������������� printf(�начальные значения семафоров %d %d\n�,
���������������������������������� outarray[0],outarray[1]);
����������������������� pause(); /* приостанов до получения сигнала */
}
else
����������������������� if (argv[1][0] == 'a')
����������������������� {��������� first = 0;
���������������������������������� second = 1;
����������������������� }
����������������������� else
����������������������� {��������� first = 1;
���������������������������������� second = 0;
����������������������� }
/* получение доступа к ранее созданному семафору */
semid = semget(SEMKEY, 2, 0777);
/* определение операций P и V */
psembuf.sem_op = -1;
psembuf.sem_flg = SEM_UNDO;
vsembuf.sem_op = 1;
vsembuf.sem_flg = SEM_UNDO;
for (count = 0; ; count++)
{
����������������������� /* закрыть первый семафор */
����������������������� psembuf.sem_num = first;
����������������������� semop(semid, &psembuf, 1);
����������������������� /* закрыть второй семафор */
����������������������� psembuf.sem_num = second;
����������������������� semop(semid, &psembuf, 1);
����������������������� printf(�процесс %d счетчик %d\n�, getpid(), count);
����������������������� /* открыть второй семафор */
����������������������� vsembuf.sem_num = second;
����������������������� semop(semid, &vsembuf, 1);
����������������������� /* открыть первый семафор */
����������������������� vsembuf.sem_num = first;
����������������������� semop(semid, &vsembuf, 1);
}
}
Предположим, что пользователь исполняет данную программу (под именем a.out) три раза в следующем порядке:
a.out &
a.out a &
a.out b &
Если программа вызывается без параметров, процесс создает набор семафоров из двух элементов и присваивает каждому семафору значение, равное 1. Затем процесс вызывает функцию pause() и приостанавливается для получения сигнала, после чего удаляет семафор из системы (cleanup).
При выполнении программы с параметром 'a' процесс (A) производит над семафорами в цикле четыре операции: он уменьшает на единицу значение семафора 0, то же самое делает с семафором 1, выполняет команду вывода на печать и вновь увеличивает значения семафоров 0 и 1. Если бы процесс попытался уменьшить значение семафора, равное 0, ему пришлось бы приостановиться, следовательно, семафор можно считать захваченным (недоступным для уменьшения). Поскольку исходные значения семафоров были равны 1 и поскольку к семафорам не было обращений со стороны других процессов, процесс A никогда не приостановится, а значения семафоров будут изменяться только между 1 и 0.
При выполнении программы с параметром 'b' процесс (B) уменьшает значения семафоров 0 и 1 в порядке, обратном ходу выполнения процесса A. Когда процессы A и B выполняются параллельно, может сложиться ситуация, в которой процесс A захватил семафор 0 и хочет захватить семафор 1, а процесс B захватил семафор 1 и хочет захватить семафор 0. Оба процесса перейдут в состояние приостанова, не имея возможности продолжить свое выполнение. Возникает взаимная блокировка, из которой процессы могут выйти только по получении сигнала.
Чтобы предотвратить возникновение подобных проблем, процессы могут выполнять одновременно несколько операций над семафорами. В последнем примере желаемый эффект достигается благодаря использованию следующих операторов:
struct sembuf psembuf[2];
psembuf[0].sem_num = 0;
psembuf[1].sem_num = 1;
psembuf[0].sem_op = -1;
psembuf[1].sem_op = -1;
semop(semid, psembuf, 2);
Psembuf - это список операций, выполняющих одновременное уменьшение значений семафоров 0 и 1. Если какая-то операция не может выполняться, процесс приостанавливается. Так, например, если значение семафора 0 равно 1, а значение семафора 1 равно 0, ядро оставит оба значения неизменными до тех пор, пока не сможет уменьшить и то, и другое.
Если процесс выполняет операцию над семафором, захватывая при этом некоторые ресурсы, и завершает свою работу без приведения семафора в исходное состояние, могут возникнуть опасные ситуации. Причинами возникновения таких ситуаций могут быть как ошибки программирования, так и сигналы, приводящие к внезапному завершению выполнения процесса. Если после того, как процесс уменьшит значения семафоров, он получит сигнал kill, восстановить прежние значения процессу уже не удастся, поскольку сигналы данного типа не анализируются процессом. Следовательно, другие процессы, пытаясь обратиться к семафорам, обнаружат, что последние заблокированы, хотя сам заблокировавший их процесс уже прекратил свое существование. Для предотвращения подобных ситуаций предназначен флаг SEM_UNDO. Если процесс установил этот флаг, то при завершении его работы ядро даст обратный ход всем операциям над семафорами, выполненным процессом.
|
Идентификатор семафора |
semid |
|
Идентификатор семафора |
semid |
semid |
|
Номер семафора |
0 |
|
Номер семафора |
0 |
1 |
|
Установленное значение |
1 |
|
Установленное значение |
1 |
1 |
(а) После первой операции����������������������� (б) После второй операции
|
Идентификатор семафора |
semid |
|
|
|
|
Номер семафора |
0 |
|
Пусто |
|
|
Установленное значение |
1 |
|
|
|
(в) После третьей операции���������������������������������� (г) После четвертой операции
Рисунок 4.4. Последовательность состояний списка структур восстановления
Ядро создает структуру восстановления всякий раз, когда процесс уменьшает значение семафора, а удаляет ее, когда процесс увеличивает значение семафора, поскольку установочное значение структуры равно 0. На Рис.3 показана последовательность состояний списка структур при выполнении программы с параметром 'a'. После первой операции процесс имеет одну структуру, состоящую из идентификатора semid, номера семафора, равного 0, и установочного значения, равного 1, а после второй операции появляется вторая структура с номером семафора, равным 1, и установочным значением, равным 1. Если процесс неожиданно завершается, ядро проходит по всем структурам и прибавляет к каждому семафору по единице, восстанавливая их значения в 0. В частном случае ядро уменьшает установочное значение для семафора 1 на третьей операции, в соответствии с увеличением значения самого семафора, и удаляет всю структуру целиком, поскольку установочное значение становится нулевым. После четвертой операции у процесса больше нет структур восстановления, поскольку все установочные значения стали нулевыми.
Векторные операции над семафорами позволяют избежать взаимных блокировок, как было показано выше, однако они представляют известную трудность для понимания и реализации, и в большинстве приложений полный набор их возможностей не является обязательным. Программы, испытывающие потребность в использовании набора семафоров, сталкиваются с возникновением взаимных блокировок на пользовательском уровне, и ядру уже нет необходимости поддерживать такие сложные формы системных функций.
ЗАДАНИЯ НА ЛАБОРАТОРНЫЕ РАБОТЫ
ЛАБОРАТОРНАЯ РАБОТА №1
Лабораторная работа посвящена изучению интерпретатора команд UNIX. Список команд, обязательных для изучения, приведен в п.2. Обратите особое внимание на перенаправление потоков ввода/вывода и программные каналы.
Внимание! При выполнении заданий необходимо использовать перенаправление ввода/вывода и программные каналы.
1. Посчитать количество пользователей в системе.
2. Отсортировать список файлов текущей директории в обратном порядке и записать его в файл.
3. Посчитать количество файлов текущего каталога, содержащих подстроку "include".
4. Посчитать, сколько раз пользователь X вошел в систему.
5. Отсортировать список текстовых файлов текущей директории в алфавитном порядке и записать его в файл.
6. Удалить из текущего каталога все файлы, содержащие подстроку "text".
7. Объединить все файлы с расширением ".txt" в один файл.
8. Посчитать, сколько процессов запущено с данного терминала.
9. Вывести на экран отсортированный в алфавитном порядке список файлов, содержащих подстроку "include".
ЛАБОРАТОРНАЯ РАБОТА № 2
Выполнение работы заключается в написании и отладке программы по одному из вариантов задания (п.6). Ввод текста программы и его редактирование производится с помощью любого текстового редактора UNIX (vi, ed и др.). Компиляция программы осуществляется с помощью следующего вызова:
$ cc имя_программы
На выходе получается исполняемый файл "a.out" или список сообщений об ошибках.
1. Написать программу, меняющую в файле местами группы байт с 21-го по 28-й и с 33-го по 40-й. Имя файла вводится в командной строке.
2. Написать программу, переписывающую из входного файла каждый n-й байт в выходной файл. Имена входного и выходного файлов вводятся в командной строке.
3. Написать программу, переписывающую все байты входного файла в выходной файл в обратном порядке. Имена входного и выходного файлов вводятся в командной строке.
4. Написать программу, осуществляющую поиск заданного шаблона (последовательности символов) в файле. При обнаружении шаблона заменить его на последовательность символов с кодом 0 такой же длины, что и длина шаблона. Имя файла и шаблон вводятся в командной строке.
5. Написать программу, осуществляющую поиск в файле последовательностей, состоящих из двух и более пробелов, и удаление всех из них, кроме первого. Имя файла вводится в командной строке.
6. Написать программу, осуществляющую сравнение двух входных файлов. Результат работы программы выводится в выходной файл и состоит либо из сообщения о том, что расхождений в файлах нет, либо следующую диагностику:������������������������������������������������������������������������������������������������������������ N�������������������� ��������������������������������������������������������������������������������������������� имя_вх_файла_1������ фрагмент_вх_файла_1�������� ���������������������������������� имя_вх_файла_2������ фрагмент_вх_файла_2������������������������������������������������������� где N - номер байта, с которого начинается расхождение; фрагмент_вх_файла - 10 байт до первого расхождения и 10 байт после. Имена файлов вводятся в командной строке.
7. Написать программу кодировки входного файла на основании заданного кодового слова с возможностью декодирования (алгоритм сложения по модулю два). Имя входного файла и кодовое слово вводятся в командной строке.
8. Написать программу, осуществляющую подсчет количества строк в текстовом файле и запись полученного числа в начало этого файла первой строкой. Имя файла вводится в командной строке.
9. Написать программу, осуществляющую подсчет количества слов в текстовом файле и запись полученного числа в начало этого файла первой строкой. Имя файла вводится в командной строке.
10.Написать программу, осуществляющую замену в файле всех символов с кодами 0-31 на пробелы. Имя файла вводится в командной строке.
11.Написать программу, разбивающую текстовый файл на страницы по N строк, то есть добавляющую в файл после каждых N строк символ перевода страницы (код 12). Имя файла и число N вводятся в командной строке.
12.Написать программу, переводящую текстовый файл из формата UNIX в формат DOS, то есть добавляющую после каждого символа перевода строки (код 10) символ возврата каретки (код 13). Имя файла вводится в командной строке.
13.Написать программу, выводящую в файл протокола список файлов указанной директории. Директория и имя файла протокола вводятся в командной строке; если имя файла не указано, список выводится на экран.
14.Написать программу, определяющую количество файлов в поддереве каталогов, начиная с указанной директории. Имя директории вводится в командной строке.
15.Написать программу, устанавливающую биты разрешения доступа по исполнению каждому файлу в указанной директории, если для этого файла разрешено исполнение хотя бы для одной группы пользователей. Имя директории вводится в командной строке.
16.Написать программу, выводящую в файл протокола список файлов указанного каталога, созданных или модифицированных в текущий день. Имена протокола и каталога вводятся в командной строке.
17.Написать программу, выводящую в файл протокола список имен владельцев файлов в указанном каталоге. Имена файла протокола и каталога вводятся в командной строке.
18.Написать программу, выводящую в файл протокола список файлов из указанного каталога, имеющих n и более ссылок. Количество ссылок n, а также имена файла протокола и каталога вводятся в командной строке.
19.Написать программу, выводящую содержимое входного файла на экран или в выходной файл (если указано его имя), а сообщения об ошибках - в любом случае на экран, используя дублирование потоков (dup). Имена входного и выходного файла вводятся в командной строке.
20.Написать программу, вводящую N байт из стандартного входного потока или из входного файла (если указано его имя) и запрашивающую количество байт N с клавиатуры (с использованием дублирования потоков (dup)). Имя входного файла вводится в командной строке.
21.Написать программу, выводящую содержимое входного файла на экран и дублирующую протокол (stderr) на экран с использованием дублирования потоков (dup). Имя входного файла вводится в командной строке.
ЛАБОРАТОРНАЯ РАБОТА № 3
1. Процесс 1 порождает потомка 2, который в свою очередь порождает потомка 3. С помощью сигналов добиться того, чтобы эти процессы заканчивались в порядке 1, 2, 3.
2. Процесс 1 порождает потомка 2. Оба процесса после этого открывают один и тот же файл и пишут в него по очереди по N байт. Организовать M циклов записи с помощью сигналов.
3. Процесс 1 открывает файл и после этого порождает потомка 2. Процесс 2 начинает запись в файл после получения сигнала SIG1 от процесса 1 и прекращает ее после получения от процесса 1 сигнала SIG2, который посылается через N секунд после SIG1. Затем процесс 1 читает данные из файла и выводит их на экран.
4. Процесс 1 открывает файл и после этого порождает потомка 2. Один процесс пишет в файл один байт, посылает другому процессу сигнал, другой читает из файла один байт, выводит прочитанное на экран и посылает сигнал первому процессу. Организовать N циклов запись/чтение.
5. Процесс 1 открывает файл и порождает потомков 2 и 3. Потомки после сигнала от предка пишут в файл по N байт, посылают сигналы процессу 1 и завершают работу. После этого процесс 1 считывает данные из файла и выводит на экран.
6. Процесс 1 открывает файл и после этого порождает потомка 2, который в свою очередь порождает потомка 3. Процесс 2 пишет N байт в общий файл, посылает сигнал процессу 3, который тоже пишет N байт в файл и посылает сигнал процессу 1, который считывает данные из файла и выводит их на экран.
7. Процесс 1 открывает файл и порождает потомка 2, после этого пишет в файл N байт и посылает сигнал процессу 2. Процесс 2 пишет N байт в файл, посылает сигнал процессу 1 и завершается. Процесс 1, получив сигнал, считывает данные из файла, выводит их на экран и завершается.
8. Процесс 1 порождает потомка 2. Оба процесса открывают один и тот же файл и записывают в него в цикле по N байт. С помощью сигналов организовать очередность записи.
9. Процесс 1 открывает файл и порождает потомков 2 и 3. Потомки пишут в файл по очереди по N байт (M циклов записи, организовать с помощью сигналов) и завершаются. Последний из них посылает сигнал процессу 1, который читает данные и выводит их на экран.
10.Процесс 1 открывает файл, порождает потомка 2, пишет в файл N байт и посылает сигнал SIG1 процессу 2. Процесс 2 по сигналу SIG1 читает данные, выводит их на экран и завершается. Если сигнал от процесса 1 не поступит в течение M секунд, процесс 2 начинает считывать данные по сигналу SIGALRM.
11.Процесс 1 открывает файл и порождает потомка 2, который в свою очередь порождает потомка 3. Процессы 2 и 3 пишут в общий файл, причем процесс 3 не может начать писать раньше, чем процесс 2. Организовать очередность с помощью сигналов. Как только размер файла превысит N байт, процесс 1 посылает потомкам сигнал SIG2 о завершении работы, считывает данные из файла и выводит их на экран.
12.Процесс 1 открывает файл и порождает потомка 2. Процесс 1 с интервалом в 1 секунду (через alarm) посылает M сигналов SIG1 процессу 2, который по каждому сигналу пишет в общий файл по N чисел. Потом процесс 1 посылает процессу 2 сигнал SIG2, процесс 2 завершается. Процесс 1 считывает данные из файла и выводит их на экран.
13.Процесс 1 открывает файл и порождает потомков 2 и 3. Процесс 1 с интервалом в 1 секунду (через alarm) по очереди посылает N сигналов SIG1 процессам 2 и 3, которые по каждому сигналу пишут в общий файл по M чисел. Потом процесс 1 посылает потомкам сигнал SIG2, процессы 2 и 3 завершаются. Процесс 1 считывает данные из файла и выводит их на экран.
14.Процесс 1 открывает два файла и порождает потомков 2 и 3. Процессы 2 и 3 с интервалом в 1 секунду (через alarm) посылают по N сигналов процессу 1, который по каждому сигналу пишет в соответствующий файл по M чисел. Потом процессы 2 и 3 считывают данные из файлов, выводят их на экран и завершаются. Процесс 1 завершается последним.
15.Процесс 1 открывает два файла и порождает потомков 2 и 3. Процессы 2 и 3 посылают по одному сигналу процессу 1, который по каждому сигналу пишет в соответствующий файл M чисел. Процессы 2 и 3 считывают данные из файлов и выводят их на экран. С помощью сигналов организовать непересекающийся вывод данных.
16.Процесс 1 открывает файл и порождает потомка 2. Процесс 2 по сигналу SIG1 от процесса 1 начинает писать в файл, по сигналу SIG2 прекращает запись, а потом по сигналу SIG1 завершается. Сигнал SIG1 поступает с задержкой в 1 секунду относительно первого сигнала SIG2.
17.Процесс 1 открывает файл и порождает потомка 2. Процесс 1 читает данные из файла, процесс 2 пишет данные в файл следующим образом: по сигналу SIG1 от процесса 1 процесс 2 записывает в файл N чисел и посылает процессу 1 сигнал окончания записи; процесс 1 по этому сигналу считывает данные и посылает процессу 2 сигнал SIG1. Процесс 2 всегда пишет данные в начало файла. Организовать M циклов записи/чтения. Прочитанные данные выводятся на экран.
18.Процесс 1 открывает существующий файл и порождает потомка 2. Процесс 1 считывает N байт из файла, выводит их на экран и посылает сигнал SIG1 процессу 2. Процесс 2 также считывает N байт из файла, выводит их на экран и посылает сигнал SIG1 процессу 1. Если одному из процессов встретился конец файла, то он посылает другому процессу сигнал SIG2 и они оба завершаются.
19.Процесс 1 открывает файл и порождает потомка 2. Оба процесса пишут в него по очереди по N чисел. Организовать M циклов записи с помощью сигналов.
20.Процесс 1 порождает потомка 2. Процесс 1 пишет в общий файл число 1, процесс 2 - число 2. Используя сигналы, обеспечить следующее содержимое файла:
а) 1 2 1 2 1 2 1 2
б) 1 1 2 2 1 1 2 2
в) 1 1 2 1 1 2 1 1 2
г) 2 1 1 2 1 1 2 1 1
д) 1 2 2 1 2 2 1 2 2
ЛАБОРАТОРНАЯ РАБОТА № 4
1. Процесс 1 порождает потомков 2 и 3, все они присоединяют к себе разделяемую память объемом (2*sizeof(int)). Процессы 1 и 2 по очереди пишут в эту память число, равное своему номеру (1 или 2). После этого один из процессов удаляет разделяемую память, затем процесс 3 считывает содержимое области разделяемой памяти и записывает в файл. Используя семафоры, обеспечить следующее содержимое файла:
а) 1 2 1 2 1 2 1 2
б) 1 1 2 2 1 1 2 2
в) 1 1 2 1 1 2 1 1 2
г) 2 1 1 2 1 1 2 1 1
д) 1 2 2 1 2 2 1 2 2
2. Процесс 1 порождает потомков 2 и 3. Все процессы записывают в общую разделяемую память число, равное своему номеру. Используя семафоры, обеспечить следующее содержимое области памяти:
а) 1 2 3 1 2 3 1 2 3
б) 1 1 2 2 3 3 1 1 2 2 3 3
в) 1 2 1 3 1 2 1 3 1 2 1 3
г) 2 1 1 3 2 1 1 3 2 1 1 3
д) 3 1 2 3 1 2 3 1 2
Последний процесс считывает содержимое разделяемой памяти, выводит его на экран и удаляет разделяемую память.
3. Процесс 1 порождает потомков 2 и 3, все они присоединяют к себе две области разделяемой памяти M1 и M2 объемом (N1*sizeof(int)) и (N2*sizeof(int)) соответственно. Процесс 1 пишет в M1 число, которое после каждой записи увеличивается на 1; процесс 2 переписывает k2 чисел из M1 в M2, а процесс 3 переписывает k3 чисел из M2 в файл. После каждого этапа работы процесс 1 засыпает на t1 секунд, процесс 2 - на t2 секунд, а процесс 3 - на t3 секунд. Процессу 1 запрещается записывать в занятую область M1; процесс 2 может переписать данные, если была произведена запись в M1 и M2 свободна; процесс 3 может переписывать данные из M2, только если была осуществлена запись в M2. Используя семафоры, обеспечить синхронизацию работы процессов в соответствии с заданными условиями. Параметры N1, N2, k1, k2, k3, t1, t2, t3 задаются в виде аргументов командной строки.
4. Процесс 1 порождает потомка 2, они присоединяют к себе разделяемую память объемом (N*sizeof(int)). Процесс 1 пишет в нее k1 чисел сразу, процесс 2 переписывает k2 чисел из памяти в файл. Процесс 1 может производить запись, только если в памяти достаточно места, а процесс 2 переписывать, только если имеется не меньше, чем k2 чисел. После каждой записи (чтения) процессы засыпают на t секунд. После каждой записи процесс 1 увеличивает значение записываемых чисел на 1. Используя семафоры, обеспечить синхронизацию работы процессов в соответствии с заданными условиями. Параметры N, k1, k2, t задаются в виде аргументов командной строки.
ЗАДАНИЯ НА КУРСОВУЮ РАБОТУ
- Разработать программу, которая просматривает текущий каталог и выводит на экран имена всех встретившихся в нем каталогов. Затем осуществляется переход в родительский каталог, который затем становится текущим, и указанные выше действия повторяются до тех пор, пока текущим каталогом не станет корневой каталог.
- Разработать программу, которая просматривает текущий каталог и выводит на экран имена всех встретившихся в нем обычных файлов. Затем осуществляется переход в родительский каталог, который затем становится текущим, и указанные выше действия повторяются до тех пор, пока текущим каталогом не станет корневой каталог.
- Разработать программу, которая выводит на экран содержимое текущего каталога в порядке возрастания размеров файлов. При этом имена каталогов должны выводиться первыми.
- Разработать программу, которая выводит на экран содержимое текущего каталога, упорядоченное по времени создания файлов. При этом имена каталогов должны выводиться последними.
- Разработать программу, которая выводит на экран содержимое текущего каталога в алфавитном порядке. Каталоги не выводить.
- Разработать программу, которая выводит на экран в текущем каталоге имена тех каталогов, которые в себе не содержат подкаталогов.
- Разработать программу, которая выводит на экран в текущем каталоге имена тех каталогов, которые содержат в себе подкаталоги.
- Разработать программу, которая осуществляет просмотр текущего каталога и выводит на экран его содержимое группами в порядке возрастания числа ссылок на файлы (в том числе имена каталогов). Группа представляет собой объединение файлов с одинаковым числом ссылок на них.
- �Пpоцесс откpывает N файлов, pеально существующие на диске, либо вновь созданные. Разpаботать пpогpамму, демонстpиpующую динамику фоpмиpования таблицы описателей файлов и изменения инфоpмации в ее элементах (пpи изменении инфоpмации в файлах). Например, сценарий программы может быть следующим:
� открытие первого пользовательского файла;
� открытие второго пользовательского файла;
� открытие третьего пользовательского файла;
� изменение размера третьего файла до нулевой длины;
� копирование второго файла в третий файл.
После каждого из этапов печатается таблица описателей файлов для всех открытых файлов.
10. Пусть N пpоцессов осуществляют доступ к одному и тому же файлу на диске (но с pазными pежимами доступа). Разpаботать пpогpамму, демонстpиpующую динамику фоpмиpования таблицы файлов и изменения ее элементов (пpи пеpемещении указателей чтения-записи, напpимеp). Например, сценарий программы может быть следующим:
� открытие файла процессом 0 для чтения;
� открытие файла процессом 1 для записи;
� открытие файла процессом 2 для добавления;
� чтение указанного числа байт файла процессом 0;
� запись указанного числа байт в файл процессом 1;
� добавление указанного числа байт в файл процессом 2.
После каждого из этапов печатаются таблицы файлов всех процессов.
11. Пусть каждый из N пpоцессов осуществляет доступ к P(i), i=1,N файлам. Далее, пусть M<N пpоцессов поpодили пpоцессы-потомки (с помощью системного вызова fork()) и сpеди этих потомков K<M пpоцессов дополнительно откpыли еще S(j),j=1,K файлов. Разpаботать пpогpамму, демонстpиpующую динамику фоpмиpования таблиц откpытых файлов пpоцессов. Например, сценарий программы может быть следующим:
� процесс 0 открывает два файла (общее число открытых файлов, включая стандартные файлы, равно пяти);
� процесс 1 открывает два файла (общее число открытых файлов, включая стандартные файлы, равно пяти);
� процесс 2 открывает два файла (общее число открытых файлов, включая стандартные файлы, равно пяти);
� процесс 0 порождает процесс 3, который наследует таблицу открытых файлов процесса 0;
� процесс 1 порождает процесс 4, который наследует таблицу открытых файлов процесса 1;
� процесс 4 дополнительно открыл еще два файла.
После каждого из этапов печатаются таблицы открытых файлов процессов, участвующих в данном этапе.
12. Разpаботайте пpогpамму, демонстpиpующую pаботу ОС UNIX пpи откpытии файла пpоцессом. Пpи этом достаточно показать только динамику создания таблиц, связанных с этим событием (таблица описателей файла, таблица файлов, таблица откpытых файлов пpоцесса). Например, сценарий программы может быть следующим:
� неявное открытие стандартного файла ввода;
� неявное открытие стандартного файла вывода;
� неявное открытие стандартного файла вывода ошибок;
� открытие первого пользовательского файла;
� открытие второго пользовательского файла;
� открытие третьего пользовательского файла.
После каждого из этапов печатаются таблица описателей файлов, таблица файлов, таблица открытых файлов процессов.
13. Пpоцесс создал новый файл и пеpеназначил на него стандаpтный вывод. Разpаботайте пpогpамму, демонстpиpующую динамику создания таблиц, связанных с этим событием (таблица файлов, таблица откpытых файлов пpоцесса). Например, сценарий программы может быть следующим:
� неявное открытие стандартного файла ввода;
� неявное открытие стандартного файла вывода;
� неявное открытие стандартного файла вывода ошибок;
� открытие пользовательского файла;
� закрытие стандартного файла ввода (моделирование close(0));
� получение копии дескриптора пользовательского файла (моделирование dup(fd), где fd - дескpиптоp пользовательского файла);
� закрытие пользовательского файла (моделирование close(fd), где fd - дескpиптоp пользовательского файла).
После каждого из этапов печатаются таблица описателей файлов, таблица файлов, таблица открытых файлов процессов.
14. Пусть два пpоцесса осуществляют доступ к одному и тому же файлу, но один из них читает файл, а дpугой пишет в него. Hаступает момент, когда оба пpоцесса обpащаются к одному и тому же блоку диска. Пусть некотоpая гипотетическая ОС использует ту же механику упpавления вводом-выводом, что и ОС UNIX, но не позволяет, как в ситуации, описанной выше, обращаться к одному блоку файла. Разработайте программу, которая демонстрирует "замораживание" перемещения указателя чтения-записи одного из процессов до тех пор, пока указатель второго процесса находится в этом блоке. Показать динамику создания всех таблиц, связанных с файлами и процессами, и изменение их содержимого.
После каждого из этапов печатаются таблицы файлов и открытых файлов обоими процессами.
15. Пусть процесс, открывший N файлов, перед порождением процесса-потомка с помощью системного вызова fork() закрывает K<N файлов. Процесс-потомок сразу после порождения закрывает M<N-K файлов и через некоторое время завершается (в это время процесс-предок ожидает его завершения). Разработайте программу, демонстрирующую динамику изменения данных в системе управления вводом-выводом ОС UNIX (таблицы файлов и таблицы открытых файлов процессов). Например, сценарий программы может быть следующим:
� открытие процессом-предком стандартных файлов ввода-вывода и четырех пользовательских файлов для чтения;
� закрытие процессом-предком двух пользовательских файлов;
� процесс-предок порождает процесс, который наследует таблицы файлов и открытых файлов процесса-предка;
� завершается процесс-потомок.
После каждого из этапов печатаются таблицы файлов и открытых файлов для обоих процессов.
16. Пусть процесс осуществляет действия в соответствии со следующим фрагментом программы:
main()
{
...
fd=creat(temporary, mode); /* открыть временный файл */
...
/* выполнение операций записи-чтения */
...
close(fd);
}
Разработайте программу, демонстрирующую динамику изменеия данных системы управления вводом-выводом ОС UNIX (таблица описателей файлов, таблица файлов, таблица открытых файлов процесса).
17. Исходный процесс создает программный канал К1 и порождает два процесса Р1 и Р2, каждый из которых готовит данные для обработки их основным процессом. Схема взаимодействия процессов показана ниже.
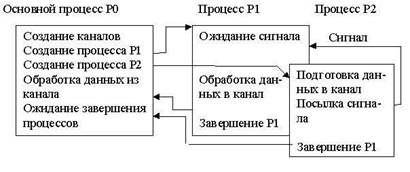
Подготовленные данные последовательно помещаются процессами-сыновьями в программный канал и передаются основному процессу.
Порядок передачи данных в канал и структура подготавливаемых данных показана ниже.
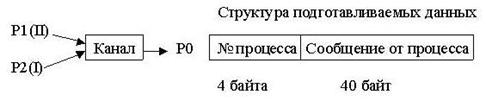
Обработка данных основным процессом заключается в чтении информации из программного канала и печати ее. Кроме того, посредством выдачи сообщений необходимо информировать обо всех этапах работы программы (создание процесса, завершение посылки данных в канал и т.д.).
18. Исходный процесс создает два программных канала К1 и К2 и порождает два процесса Р1 и Р2, каждый из которых готовит данные для обработки их основным процессом. Схему взаимодействия процессов и структуру подготавливаемых данных см. в варианте 1.
Подготавливаемые данные процесс Р2 помещает в канал К1, затем они оттуда читаются процессом Р1, переписываются в канал К2, дополняются своими данными. Порядок передачи данных в канал изображен ниже

Обработка данных основным процессом заключается в чтении информации из программного канала К2 и печати ее. Кроме того, посредством выдачи сообщений необходимо информировать обо всех этапах работы программы (создание процесса, завершение посылки данных в канал и т.д.).
19. Исходный процесс создает программный канал К1 и порождает новый процесс Р1, а тот, в свою очередь, еще один процесс Р2, каждый из которых готовит данные для обработки их основным процессом. Схема взаимодействия процессов показана ниже.
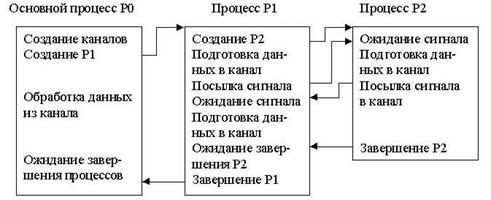
Подготовленные данные последовательно помещаются процессами-сыновьями в программный канал и передаются основному процессу.
Порядок передачи данных в канал и структура подготавливаемых данных показана ниже.

Обработка данных основным процессом заключается в чтении информации из программного канала и печати ее. Кроме того, посредством выдачи сообщений необходимо информировать обо всех этапах работы программы (создание процесса, завершение посылки данных в канал и т.д.).
20. Исходный процесс создает два программных канала К1 и К2 и порождает новый процесс Р1, а тот, в свою очередь, еще один процесс Р2, каждый из которых готовит данные для обработки их основным процессом. Схему взаимодействия процессов и структуру подготавливаемых данных см. в варианте 3.
Подготавливаемые данные процесс Р1 помещает в канал К1, а процесс Р2 в канал К2, откуда они процессом Р1 копируются в канал К1 и дополняются новой порцией данных. Порядок передачи данных в канал изображен ниже

Обработка данных основным процессом заключается в чтении информации из программного канала К1 и печати ее. Кроме того, посредством выдачи сообщений необходимо информировать обо всех этапах работы программы (создание процесса, завершение посылки данных в канал и т.д.).
21. Программа порождает иерархическое дерево процессов. Каждый процесс выводит сообщение о начале выполнения, создает пару процессов, сообщает об этом, ждет завершения порожденных процессов и затем заканчивает работу. Поскольку действия в рамках каждого процесса однотипны, эти действия должны быть оформлены отдельной программой, загружаемой системным вызовом exec(). Параметр программы - число уровней (не более 5).
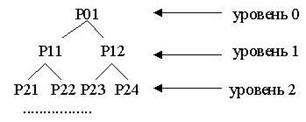
22. Исходный процесс создает программный информационный канал К1, канал синхронизации К0 и порождает два процесса Р1 и Р2, из которых один (Р1) порождает еще один процесс Р3. Назначение всех трех порожденных процессов - подготовка данных для обработки их основным процессом. Схема взаимодействия процессов показана ниже.
Подготовленные данные последовательно помещаются процессами-сыновьями в программный канал К1 и передаются основному процессу. Кроме того, процесс Р1 через канал синхронизации К0 сообщает процессу Р2 идентификатор процесса Р3 с тем, чтобы процесс Р2 мог послать процессу Р3 сигнал. Порядок передачи данных в канал и структура подготавливаемых данных показана ниже.
Обработка данных основным процессом заключается в чтении информации из программного канала и печати ее. Кроме того, посредством выдачи сообщений необходимо информировать обо всех этапах работы программы (создание процесса, завершение посылки данных в канал и т.д.).
23. Исходный процесс создает два программных информационных канала К1 и К2, канал синхронизации К0 и порождает два процесса Р1 и Р2, из которых один (Р1) порождает еще один процесс Р3. Назначение всех трех порожденных процессов - подготовка данных для обработки их основным процессом. Схему взаимодействия процессов и структуру подготавливаемых данных см. в варианте 6.
Подготавливаемые данные процесс Р3 помещает в канал К1, а процессы Р1 и Р2 в канал К2, откуда они процессом Р3 копируются в канал К1 и дополняются новой порцией данных. Кроме того, процесс Р1 через канал синхронизации К0 сообщает процессу Р2 идентификатор процесса Р3 с тем, чтобы процесс Р2 мог послать процессу Р3 сигнал. Порядок передачи данных в канал показан ниже.

Обработка данных основным процессом заключается в чтении информации из программного канала К1 и печати ее. Кроме того, посредством выдачи сообщений необходимо информировать обо всех этапах работы программы (создание процесса, завершение посылки данных в канал и т.д.).
24. Исходный процесс создает программный канал К1 и порождает новый процесса Р1, а тот, в свою очередь, порождает еще один процесс Р2. Схема взаимодействия процессов показана ниже.
Подготовленные данные последовательно помещаются процессами-сыновьями в программный канал и передаются основному процессу. Файл, читаемый процессом Р2, должен быть достаточно велик с тем, чтобы его чтение не завершилось ранее, чем закончится установленная задержка в n секунд. После срабатывания будильника процесс Р1 посылает сигнал процессу Р2, прерывая чтение файла.
Порядок передачи данных в канал и структура подготавливаемых данных показана ниже.
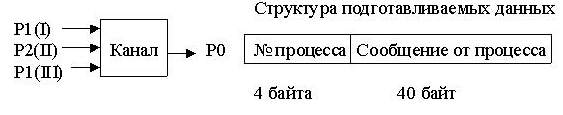
Обработка данных основным процессом заключается в чтении информации из программного канала и печати ее. Кроме того, посредством выдачи сообщений необходимо информировать обо всех этапах работы программы (создание процесса, завершение посылки данных в канал и т.д.).