 |
|
|
ВВЕДЕНИЕ
В настоящее время большинство предприятий нашей страны находится в процессе осуществления комплексной автоматизации своей деятельности. Комплексная автоматизация производится либо путем внедрения и настройки коммерческих систем класса ERP, MRP, PDM, либо путем проектирования и разработки собственного программного обеспечения. В основе любой комплексной автоматизированной системы лежит база данных (БД), как правило, реляционная. Одним из важнейших этапов создания новой автоматизированной системы предприятия является разработка проекта БД. В случае внедрения готовой системы на этапе ее настройки требуется перепроектирование БД.
Особенностью комплексной автоматизированной системы является сложность БД, которая содержит информацию о большом количестве разнородных объектов и связях между ними. Сложность проектирования БД требует использования методологий, основанных на моделировании данных. От специалистов, занимающихся разработкой или эксплуатацией автоматизированных систем предприятий требуется их знание.
Цель данной работы - привить основные навыки проектирования реляционных БД с помощью современных технологий.
1. ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ БАЗ ДАННЫХ
База данных - именованная структурированная совокупность данных на внешнем носителе, отражающая состояние объектов и их отношений в рассматриваемой предметной области.
БД должна содержать все обрабатываемые в автоматизированной системе первичные данные. При этом, не допускается дублирование данных, т.е. описание любого объекта предметной области должно храниться только в одном месте. Каждая БД строится в соответствии с определенной моделью данных.
Модель данных - совокупность методов и средств, в соответствии с которыми данные структурируются� и выполняются операции над этими данными. Согласно Кодду она содержит три компонента:
- средства определения допустимых структур данных;
- множество операций, применимых к допустимому состоянию БД для поиска и модификации данных;
- множество ограничений целостности, определяющих допустимые состояния БД [1].
Наиболее распространены следующие модели данных: иерархическая, сетевая, реляционная, объектная.
Чаще всего на практике используются реляционные БД. Однако, в последние несколько лет серьезно развиваются объектные БД, основная область применения которых сейчас – автоматизация проектно-конструкторской деятельности.
 |
Рис. 1. Уровни модели БД
Система управления базами данных (СУБД) - совокупность языковых и программных средств, предназначенных для создания, ведения и совместного применения БД многими пользователями [2].
Модель базы данных -� описание конкретной базы данных средствами определенного языка (не всегда формального).
���� Существует три уровня модели БД: логическая (инфологическая), физическая (даталогическая) и� модель внутреннего представления (физическая)[1] (рис.1 [4]).
���� Логическая модель БД используется проектировщиками, администраторами и пользователями. Хотя, в принципе, не требуется, чтобы логическая модель описывалась на формальном языке, в настоящее время ее принято описывать на языке диаграмм �сущность-связь�, в основе которых лежит формальная ER-модель П. Чена. Это позволяет осуществлять автоматический переход к физической модели.
����
2. РЕЛЯЦИОННАЯ МОДЕЛЬ ДАННЫХ
Реляционные БД являются наиболее распространенным в настоящее время, хотя наряду с общепризнанными достоинствами обладают и рядом недостатков. К числу достоинств реляционного подхода можно отнести:
- наличие небольшого набора абстрактных структур, которые позволяют достаточно просто моделировать большую часть предметных областей и допускают точные формальные определения, оставаясь интуитивно понятными;
- наличие мощного математического аппарата, опирающегося на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных;
- возможность ненавигационного манипулирования данными без необходимости знания физической организации баз данных во внешней памяти.
Сейчас основным предметом критики реляционных БД является присущая им ограниченность� при использование в так называемых нетрадиционных областях, например, в системах автоматизированного проектирования, в которых требуются предельно сложные структуры данных. Еще одним часто отмечаемым недостатком реляционных баз данных является невозможность адекватного отражения семантики предметной области. Другими словами, возможности представления знаний о семантической специфике предметной области в реляционных системах сильно ограничены. Современные исследования в области разработки новых систем главным образом посвящены устранению этих недостатков.
Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение.
Для начала покажем смысл этих понятий на примере отношения СОТРУДНИКИ, содержащего информацию о сотрудниках некоторой организации [2]:
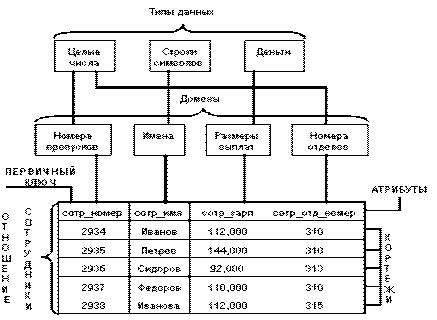
Рис. 2 Основные понятия реляционных БД [2]
Тип данных в реляционной модели данных полностью адекватен понятию простого типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных, а также специальных "темпоральных" данных (дата, время). В нашем примере мы имеем дело с данными трех типов: строки символов, целые числа и "деньги".
Домен имеет некоторые аналогии с подтипами в некоторых языках программирования. Домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения (предиката), применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат "истина", то элемент данных считается элементом домена. Наиболее правильной интуитивной трактовкой понятия домена является понимание домена как допустимого потенциального множества значений данного типа. Например, домен "Имена" в нашем примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать имя (в частности, такие строки не могут начинаться с мягкого знака) [2].
Схема отношения - это именованное множество пар {имя атрибута, имя домена (или типа данных)}. Степенью или "арностью" схемы отношения называют мощность этого множества. Степень отношения СОТРУДНИКИ равна четырем, то есть оно является 4-арным.
Схема базы данных� - это набор именованных схем отношений.
Кортеж, соответствующий данной схеме отношения, - это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. "Значение" является допустимым значением домена данного атрибута (или типа данных). Тем самым, степень или "арность" кортежа, т.е. число элементов в нем, совпадает с "арностью" соответствующей схемы отношения. Можно сказать, что кортеж - это набор именованных значений заданного типа [2].
Отношение - это множество кортежей, соответствующих одной схеме отношения. Понятие схемы отношения ближе всего к понятию структурного типа данных в процедурных или объектно-ориентированных языках программирования. С точки зрения языков программирования было бы логично разрешать отдельно определять схему отношения, а затем одно или несколько отношений с данной схемой.
Однако в реляционных базах данных это не принято. Имя схемы отношения в здесь всегда совпадает с именем соответствующего отношения-экземпляра. В классических реляционных базах данных после определения схемы базы данных изменяются только отношения-экземпляры. В них могут появляться новые и удаляться или модифицироваться существующие кортежи. Однако в большинстве СУБД допускается и изменение схемы базы данных: определение новых и изменение существующих схем отношений. Такой процесс принято называть эволюцией схемы базы данных.
Обычным житейским представлением отношения является таблица, заголовком которой является схема отношения, а строками - кортежи отношения-экземпляра; в этом случае имена атрибутов именуют столбцы этой таблицы. Поэтому иногда говорят "столбец таблицы", имея в виду "атрибут отношения". Этой терминологии придерживаются в большинстве коммерческих реляционных СУБД, а также в стандартизированном языке манипулирования данными SQL.
Реляционная база данных - это набор отношений, имена которых совпадают с именами схем отношений в схеме БД [2].
Как видно, основные структурные понятия реляционной модели данных� имеют достаточно простую интуитивную интерпретацию, хотя в реляционной теории все они определяются формально и математически строго.
Рассмотрим теперь наиболее важные свойства отношений, которые следуют из приведенных ранее определений:
1. Отсутствие кортежей-дубликатов. Это свойство следует из определения отношения как множества кортежей. В классической теории множеств по определению каждое множество состоит из различных элементов.
Из этого свойства вытекает наличие у каждого отношения так называемого первичного ключа - набора атрибутов, значения которых однозначно определяют кортеж отношения. Для каждого отношения по крайней мере полный набор его атрибутов обладает этим свойством. Однако формальное определение первичного ключа требует обеспечения его "минимальности", т.е. в набор атрибутов первичного ключа не должны входить такие атрибуты, которые можно отбросить без ущерба для основного свойства - однозначно определять кортеж. Понятие первичного ключа является исключительно важным для определения понятия целостности баз данных.
2. Отсутствие упорядоченности кортежей. Это также является следствием определения отношения как множества кортежей. Отсутствие требования к поддержанию порядка на множестве кортежей отношения дает дополнительную гибкость СУБД при хранении баз данных во внешней памяти и при выполнении запросов к базе данных. Это не противоречит тому, что при формулировании запроса к БД, например, на языке SQL можно потребовать сортировки результата в соответствии со значениями некоторых столбцов. Такой результат, вообще говоря, не отношение, а некоторый упорядоченный список кортежей.
3. Отсутствие упорядоченности атрибутов. Атрибуты отношений не упорядочены, поскольку по определению схема отношения есть множество пар {имя атрибута, имя домена}. Для ссылки на значение атрибута в кортеже отношения всегда используется имя атрибута. Это свойство теоретически позволяет, например, модифицировать схемы существующих отношений не только путем добавления новых атрибутов, но и путем удаления существующих атрибутов. Если упорядоченность набора атрибутов отношения явно не требуется, часто в качестве неявного порядка атрибутов используется их порядок в линейной форме определения схемы отношения.
4. Атомарность значений атрибутов. Значения всех атрибутов являются атомарными. Это следует из определения домена как потенциального множества значений простого типа данных, т.е. среди значений домена не могут содержаться множества значений (отношения).
Теперь перейдем к рассмотрению реляционной модели данных непосредственно. Согласно Дейту, реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части [2].
В структурной части модели фиксируется, что единственной структурой данных, используемой в реляционных БД, является нормализованное n-арное отношение (nÎN). Под нормализацией подразумевается то что все атрибуты отношения атомарны и нет двух различных атрибутов, имеющих одинаковый смысл (первая нормальная форма). По сути дела, в данном разделе мы рассматривали именно понятия и свойства структурной части реляционной модели.
В манипуляционной части модели утверждаются два фундаментальных механизма манипулирования реляционными БД - реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями), а второй - на классической логике предикатов первого порядка. Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
Наконец, в целостной состовляющей реляционной модели данных фиксируются два базовых требования, которые должны поддерживаться в любой реляционной СУБД. Первое требование называется требованием целостности сущностей. Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений. Конкретно требование состоит в том, что любой кортеж любого отношения должен быть отличим от любого другого кортежа этого отношения. Другими словами, любое отношение должно обладать первичным ключом [2].
Второе требование называется требованием целостности по ссылкам. При соблюдении нормализованности отношений сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений. Например, представим, что нам требуется представить в реляционной базе данных сущность ОТДЕЛ с атрибутами ОТД_НОМЕР (номер отдела), ОТД_КОЛ (количество сотрудников) и ОТД_СОТР (набор сотрудников отдела). Для каждого сотрудника нужно хранить СОТР_НОМЕР (номер сотрудника), СОТР_ИМЯ (имя сотрудника) и СОТР_ЗАРП (заработная плата сотрудника). Как мы вскоре увидим, при правильном проектировании соответствующей БД в ней появятся два отношения: ОТДЕЛЫ ( ОТД_НОМЕР, ОТД_КОЛ ) (первичный ключ - ОТД_НОМЕР) и СОТРУДНИКИ ( СОТР_НОМЕР, СОТР_ИМЯ, СОТР_ЗАРП, СОТР_ОТД_НОМ ) (первичный ключ - СОТР_НОМЕР).
Как видно, атрибут СОТР_ОТД_НОМ появляется в отношении СОТРУДНИКИ не потому, что номер отдела является собственным свойством сотрудника, а лишь для того, чтобы иметь возможность восстановить при необходимости полную сущность ОТДЕЛ. Значение атрибута СОТР_ОТД_НОМ в любом кортеже отношения СОТРУДНИКИ должно соответствовать значению атрибута ОТД_НОМ в некотором кортеже отношения ОТДЕЛЫ. Атрибут такого рода называется внешним ключом, поскольку его значения однозначно характеризуют сущности, представленные кортежами некоторого другого отношения (т.е. задают значения их первичного ключа). Говорят, что отношение, в котором определен внешний ключ, ссылается на соответствующее отношение, в котором такой же атрибут является первичным ключом [2].
Требование целостности по ссылкам, или требование внешнего ключа заключается в том, что для каждого значения внешнего ключа в ссылающемся отношении, должен найтись кортеж с таким же значением первичного ключа в отношении, на которое ведет ссылка, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать). В приведенном примере это означает, что если для сотрудника указан номер отдела, то этот отдел должен существовать.
Ограничения целостности сущности и по ссылкам должны поддерживаться СУБД. Для соблюдения целостности сущности достаточно гарантировать отсутствие в любом отношении кортежей с одним и тем же значением первичного ключа. Поддержание целостности по ссылкам несколько более сложная задача.
При обновлении ссылающегося отношения (вставке новых кортежей или модификации значения внешнего ключа в существующих кортежах) достаточно следить за тем, чтобы не появлялись некорректные значения внешнего ключа. Но целостность необходимо поддерживать и� при удалении кортежа из отношения, на которое ведет ссылка.
Здесь существуют три подхода, каждый из которых поддерживает целостность по ссылкам. Первый подход заключается в том, что запрещается производить удаление кортежа, на который существуют ссылки (т.е. сначала нужно либо удалить ссылающиеся кортежи, либо соответствующим образом изменить значения их внешнего ключа). Второй подход заключается в том, что при удалении кортежа, на который имеются ссылки, во всех ссылающихся кортежах значение внешнего ключа автоматически становится неопределенным. Наконец, третий подход (каскадное удаление) состоит в том, что при удалении кортежа из отношения, на которое ведет ссылка, из ссылающегося отношения автоматически удаляются все ссылающиеся кортежи. Современные СУБД позволяют использовать все три подхода.
3. ЛОГИЧЕСКАЯ МОДЕЛЬ БД
Цель логического моделирования состоит в обеспечении разработчика ИС простой для понимания схемой базы данных в форме одной модели или нескольких локальных моделей, которые относительно легко могут быть отображены в любую систему баз данных. Поскольку основным инструментом логического моделирования является модель �сущность-связь� (ER-модель) П.Чена, данный раздел посвящен ее рассмотрению [3, 4, 5].
Основными элементами ER-модели являются сущности, связи между ними и их свойства (атрибуты).
Сущность – категория различимых объектов предметной области, обладающих общими свойствами. Примеры сущностей: человек, место, самолет, рейсы, вкус, цвет и т.д. Необходимо различать такие понятия, как сущность и экземпляр сущности. Понятие сущности относится к набору однородных личностей, предметов, событий или идей, выступающих как целое. Экземпляр сущности относится к конкретной вещи в наборе. Например, сущностью может быть ГОРОД, а экземпляром – Москва, Киев и т.д.
Атрибут – любая характеристика сущности, значимая для рассматриваемой предметной области и предназначенная для идентификации, классификации, квалификации, количественной характеристики или выражения состояния сущности. Атрибут представляет тип характеристик или свойств, ассоциированных со множеством реальных или абстрактных объектов (людей, мест, событий, состояний, идей, пар предметов и т.д.). Экземпляр атрибута - это определенная характеристика отдельного элемента множества. Экземпляр атрибута определяется типом характеристики и ее значением, называемым значением атрибута. В ER-модели атрибуты ассоциируются с конкретными сущностями. Таким образом, экземпляр сущности должен обладать единственным определенным значением для ассоциированного атрибута.
Атрибут может быть либо обязательным, либо необязательным. Обязательность означает, что атрибут не может принимать неопределенных значений. Атрибут может быть либо описательным, либо входить в состав первичного ключа.
Абсолютное различие между сущностями и атрибутами отсутствует. Атрибут является таковым только в связи с сущностью. В другом контексте атрибут может выступать как самостоятельная сущность. Например, для автомобильного завода цвет – это только атрибут продукта производства, а для лакокрасочной фабрики цвет –сущность [3].
Первичный ключ – минимальный набор атрибутов, по значениям которых можно однозначно идентифицировать требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся.
Связь – ассоциирование двух или более сущностей. Одно из основных требований к организации базы данных – это обеспечение возможности отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи (по первичным и внешним ключам). А так как в реальных базах данных нередко содержатся сотни или даже тысячи сущностей, то теоретически между ними может быть установлено более миллиона связей. Наличие такого множества связей и определяет сложность логических моделей.
Связь - это ассоциация между сущностями, при которой, как правило, каждый экземпляр одной сущности, называемой родительской сущностью, ассоциирован с произвольным (в том числе нулевым) количеством экземпляров второй сущности, называемой сущностью-потомком, а каждый экземпляр сущности-потомка ассоциирован в точности с одним экземпляром сущности-родителя. Таким образом, экземпляр сущности-потомка может существовать только при существовании сущности родителя. Это совершенно согласуется с ограничениями целостности по ссылкам в реляционной модели данных.
В зависимости от того какое количество экземпляров сущности-потомка может быть связано с экземпляром сущности-родителя связи подразделяются на:
1. Один-ко-многим. Одному экземпляру сущности-родителя может соответствовать несколько (в т.ч. ноль) экземпляров сущности-потомка. Например, сущности АУДИТОРИЯ и КОМПЬЮТЕР ассоциируются связью один-ко-многим, поскольку в одной аудитории может находиться несколько компьютеров, в то время как каждый компьютер может находиться строго в одной аудитории.
2. Один-к-одному. Одному экземпляру сущности-родителя может соответствовать не более одного экземпляра сущности-потомка. Такая связь, например, может быть образована между сущностями СТУДЕНТ и ПАСПОРТ, если по какой-либо причине (например, для удобства моделирования или раздельного использования) паспортные данные должны рассматриваться отдельно.
Кроме того, на этапе моделирования допускается использовать связи многие-ко-многим, которые затем должны быть преобразованы путем введения дополнительной сущности-ассоциации и двух связей один-ко-многим.
При связывании сущностей первичный ключ родителя мигрирует в потомка, где образует внешний ключ. Собственно в БД связывание происходит по равенству значений первичного ключа родителя и соответствующего ему внешнего ключа в потомке. Внешний ключ может мигрировать в состав первичного ключа потомка. В этом случае связь называется идентифицирующей. В противном случае связь является неидентифицирующей. Если связь идентифицирующая, то сущность-потомок является зависимой и определяется только посредством родителя (или родителей, если их несколько).
Связи может даваться имя, выражаемое грамматическим оборотом глагола. Имя каждой связи между двумя данными сущностями должно быть уникальным, но имена связей в модели могут повторяться. Имя связи всегда формируется с точки зрения родителя, так что предложение может быть образовано соединением имени сущности-родителя, имени связи, выражения степени и имени сущности-потомка [3].
4. ER-ДИГРАММЫ. НОТАЦИЯ IDEF1X
Наиболее удобным способом представления модели �сущность-связь� является набор ER-диаграмм. В ER-диаграмме элементы модели отображаются графическими объектами. Существует несколько нотаций для ER-диаграмм. В данном разделе мы разберем нотацию IDEF1X (Integration DEFinition for information modeling).
 ���������������������������
��������������������������� 
a) б)
Рис 3. Сущности в нотации IDEF1X
а) независимая сущность; б) зависимая сущность.
На рис. 3 представлены примеры изображения сущностей в нотации IDEF1X. Независимая сущность изображается обыкновенным прямоугольником, зависимая – прямоугольником с закругленными краями. Имя сущности пишется сверху над прямоугольником.� Прямоугольник разделен горизонтальной чертой на две части. В верхней части указываются ключевые атрибуты (т.е. атрибуты, входящие в состав первичного ключа). Под чертой перечисляются имена всех неключевых атрибутов. Справа от имени внешнего ключа в круглых скобках ставится FK (Foreign Key). В логической модели допускаются любые имена сущностей и атрибутов в т.ч. и русскоязычные.
В физической модели имена сущностей и атрибутов должны соответствовать правилам именования таблиц и полей в выбранной СУБД. Справа от имен атрибутов через двоеточье указываются типы данных или домены, к которым они относятся.
�������������������
����������
 ������������������������
������������������������
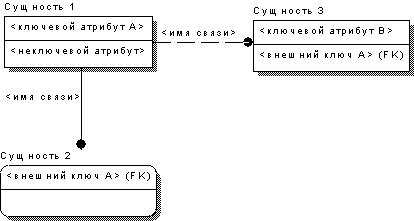
Рис 5. Связи в нотации IDEF1X.
На рис. 5 показаны примеры связей в нотации IDEF1X. Идентифицирующая связь представляется сплошной линией, неидентифицирующая – штриховой. Линии могут быть ломанными. Имя связи пишется либо сверху, либо слева от линии. Обе связи в данном примере имеют тип один-ко-многим. Родительской� (главной) сущностью является �Сущность 1�. Связи один-к-одному изображаются как связи один-ко-многим. Связь типа многие-ко-многим изображается линией с черными шариками на обоих концах. Использовать такие связи в модели не рекомендуется, поскольку, как уже было сказано, они не представимы в реляционных БД, и их необходимо преобразовывать. Кстати, большинство современных программных средств проектирования БД осуществляют это преобразование автоматически.
5. CASE-СРЕДСТВА
Для проектирования БД используют так называемые CASE-средства (Computed-Aided Software/System Engineering).
Современные CASE-средства охватывают обширную область поддержки технологий проектирования ИС в целом: от простых средств анализа и документирования до полномасштабных средств автоматизации, охватывающих весь жизненный цикл ПО ИС.
Наиболее трудоемкими этапами разработки ИС являются этапы анализа и проектирования, в процессе которых CASE-средства позволяют повысить качество принимаемых технических решений и подготовить проектную документацию. При этом большую роль играют методы визуального представления информации. Это предполагает построение структурных или иных диаграмм в реальном масштабе времени и сквозную проверку синтаксических правил. Графические средства моделирования предметной области позволяют разработчикам в наглядном виде изучать существующую ИС, перестраивать ее в соответствии с поставленными целями и имеющимися ограничениями.
В разряд CASE-средств попадают как относительно дешевые системы для персональных компьютеров с весьма ограниченными возможностями, так и дорогостоящие системы для неоднородных вычислительных платформ и операционных сред. Современный рынок программного обеспечения насчитывает около 300 различных CASE-средств, наиболее мощные из которых используются практически всеми ведущими западными фирмами.
Обычно к CASE-средствам относят любое программное средство, автоматизирующее ту или иную совокупность процессов жизненного цикла ПО и обладающее следующими характерными особенностями:
- мощные графические средства для описания и документирования ИС, обеспечивающие удобный интерфейс с разработчиком и развивающие его творческие возможности;
- интеграция отдельных компонент CASE-средств, обеспечивающая управляемость процессом разработки ИС;
- использование специальным образом организованного хранилища проектных метаданных (репозитория).
Все современные CASE-средства могут быть классифицированы по типам и категориям [5]. Классификация по типам отражает функциональную ориентацию CASE-средств. Классификация по категориям определяет степень интегрированности по выполняемым функциям и включает отдельные локальные средства, решающие небольшие автономные задачи (tools), набор частично интегрированных средств, охватывающих большинство этапов жизненного цикла ИС (toolkit) и полностью интегрированные средства, поддерживающие весь жизненный цикл ИС и связанные общим репозиторием. Помимо этого, CASE-средства можно классифицировать по следующим признакам:
- применяемым методологиям и моделям систем и БД;
- степени интегрированности с СУБД;
- доступным платформам.
Классификация по типам в основном совпадает с компонентным составом CASE-средств и включает следующие типы:
- средства анализа (Upper CASE), предназначенные для построения и анализа моделей предметной области;
- средства анализа и проектирования (Middle CASE), поддерживающие наиболее распространенные методологии проектирования и использующиеся для создания проектных спецификаций. Выходом таких средств являются спецификации компонентов и интерфейсов системы, архитектуры системы, алгоритмов и структур данных;
- средства проектирования баз данных, обеспечивающие моделирование данных и генерацию схем баз данных для наиболее распространенных СУБД. К ним относятся ERwin, Case Studio и DataBase Designer (ORACLE);
- �средства реинжиниринга, обеспечивающие анализ программных кодов и схем баз данных и формирование на их основе различных моделей и проектных спецификаций. Средства анализа схем БД и формирования ER-диаграмм входят в состав Vantage Team Builder,� Silverrun, Designer/2000, ERwin и Case Studio.
Собственно средства моделирования баз данных должны поддерживать следующие функции:
- автоматизированная разработка логической модели базы в виде ER-диаграмм;
- поддержка разбиения модели БД на субмодели и их синхронизация;
- автоматизированное преобразования логической модели в физическую, соответствующую одной из выбранных СУБД;
- автоматическое формирование скриптов на языке SQL;
- реинжиниринг реляционных БД;
- поддержка репозитория;
- интеграция со средствами проектирования функциональной модели ИС;
- синхронизация версий проекта;
- создание отчетов (как правило, в форматах HTML или XML) о модели БД.
Перечисленным функциональным набором обладают большинство современных CASE-средств проектирования БД. Автор отдает предпочтение таким средствам как Erwin, BPWin и CASE Studio, однако осознает, что и другие системы могут вполне удовлетворить основные потребности проектировщика.
6. ЭТАПЫ ПРОЕКТИРОВАНИЯ БД
Проектирование БД – один из начальных и основных этапов создания новой автоматизированной системы. Результат проектирования - физическая модель БД, которая описывает ее в терминах языка, принятого в конкретной СУБД. В свою очередь, процесс проектирования делится на следующие этапы:
1. Анализ предметной области. Выявляются объекты предметной области (сущности). Строится начальный вариант логической модели. В терминах принятого языка описываются сущности (категории объектов предметной области) и их атрибуты. Определяются первичные ключи и связи между сущностями предметной области.
2. Преобразование связей многие-ко-многим.
3. Нормализация логической модели БД.
4. Построение физической модели: определение имен, типов и/или доменов атрибутов.
Следует заметить, что на практике процесс проектирования может быть итеративным, т.е. возможен возврат с одного из этапов на любой предыдущий.
6.1. Анализ предметной области и построение
начального варианта ER-диаграммы
На данном этапе задача заключается в выявлении основных сущностей предметной области, их атрибутов и связей между ними, исходя из ее описания. Общепринятой методологии решения данной задачи нет (или таковая неизвестна автору). Известно только, что на основании только предварительного описания выявить все сущности, как правило, не удается. Поэтому предварительное описание должно быть уточнено. С этой целью производятся следующие действия по извлечению дополнительной информации:
1. Анкетирование. Анкеты позволяют составить грубое представление о предметной области. Список вопросов должен быть ограничен 15-20. Вопросы должны позволить выявить основные входные и выходные потоки данных, и описываемые ими объекты.
2. Сбор документов. Если к моменту начала разработки имеются документы, которые поступают в ИС или должны в ней рассчитываться, то они должны быть обязательно собраны.
3. Интервьюирование необходимый метод сбора информации. Применяется для уточнения сведений, полученных на основе анкетирования и собранных документов. Интервьюирование является наиболее важной и сложной задачей, так как должно привести к выявлению всех �мелочей�, без которых проектирование БД невозможно.
В работе [3] представлены общие рекомендации к тому, как проводить анализ предметной области. В дополнение к ним можно дать следующий совет: прежде всего следует обращать внимание на выходные данные, т.е. ту информацию, которую должна генерировать ИС. При описании предметной области заказчик может обращать внимание на сущности, которые важны для него, однако в последствии выясняется, что в БД эти сущности представлять не надо. Объекты, которые упоминаются заказчиком при формулировании его информационных потребностей, требуют наибольшего внимания. Это объясняется тем, что на практике такие объекты, как правило, должны отображаться в БД.
Логическая модель БД может строиться уже на основе предварительного описания предметной области. По мере его уточнения, модель изменяется и совершенствуется. Сначала выявляются сущности, затем их атрибуты, затем определяются первичные ключи и затем связи.
6.2. Преобразование связей многие-ко-многим
Данное преобразование осуществляется по следующему алгоритму:
1. Создается новая сущность (сущность-ассоциация).
2. Между связанными сущностями и сущностью-ассоциацией устанавливаются две идентифицирующие связи один-ко-многим (сущность-ассоциация выступает в качестве подчиненной).
3. Связь многие-ко-многим удаляется.
Пример преобразования связи показан на рис.6.
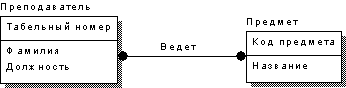
а)

б)
Рис 6. Преобразование связи многие-ко-многим
а) до преобразования; б)после преобразования.
6.3. Нормализация БД
Как уже говорилось выше, БД должна быть нормализована. Существует несколько нормальных форм БД. Каждой нормальной форме соответствует некоторый определенный набор ограничений, и отношение находится в некоторой нормальной форме, если удовлетворяет свойственному ей набору ограничений.
�В теории реляционных БД обычно выделяется следующая последовательность нормальных форм:
- первая нормальная форма (1NF);
- вторая нормальная форма (2NF);
- третья нормальная форма (3NF);
- нормальная форма Бойса-Кодда (BCNF);
- четвертая нормальная форма (4NF);
- пятая нормальная форма, или нормальная форма проекции-соединения (5NF или PJ/NF).
Основные свойства нормальных форм:
- каждая следующая нормальная форма в некотором смысле лучше предыдущей;
- при переходе к следующей нормальной форме свойства предыдущих нормальных свойств сохраняются.
В основе процесса нормализации лежит метод декомпозиции отношения, находящегося в предыдущей нормальной форме, в два или более отношения, удовлетворяющих требованиям следующей нормальной формы.
Предварительно дадим несколько определений.
1. Функциональная зависимость.
В отношении R атрибут Y функционально зависит от атрибута X (X и Y могут быть составными) в том и только в том случае, если каждому значению X соответствует в точности одно значение Y [2].
2. Полная функциональная зависимость
Функциональная зависимость атрибута Y от атрибута X в отношении R называется полной, если атрибут Y не зависит функционально от любого точного подмножества X.
3. Транзитивная функциональная зависимость
Функциональная зависимость атрибута Y от атрибута X в отношении R называется транзитивной, если существует такой атрибут Z, что имеются функциональные зависимости Z от Х и атрибута Y от Z и отсутствует функциональная зависимость атрибута X от Z.
�Отношение находится в первой нормальной форме (1NF) тогда, когда все атрибуты атомарны и отсутствуют повторяющиеся группы.
Атомарность (неделимость) атрибутов определяется относительно рассматриваемой предметной области. Например, такое понятие как адрес, включает в себя, как минимум, город, улицу, дом и т.д. В зависимости от предметной области адрес может быть представлен одним или большим числом атрибутов. Например, если адрес требуется только для отправки корреспонденции, то для него достаточно одного атрибута. Если же требуется анализировать количество адресатов в различных городах, то для адреса необходимо использовать два атрибута: город и городской адрес.
Под повторяющейся группой подразумевается набор атрибутов, имеющих одно и тоже смысловое значение. Например, мы описываем сущность �организация� и знаем, что у любой организации, в принципе, может быть несколько телефонов. Если мы введем в сущность атрибуты �телефон 1�, �телефон 2� и т.д., то они образуют повторяющуюся группу, и отношение станет ненормализованным. В данном случае необходимо создать сущность �телефон� и связать с ней сущность �организация� связью один-ко-многим.
Отношение находится во второй нормальной форме (2NF) в том и только в том случае, когда находится в 1NF, и каждый неключевой атрибут полностью зависит от первичного ключа (или от каждого ключа, если их несколько).
Отношение находится в третьей нормальной форме (3NF) в том и только в том случае, если находится в 2NF и каждый неключевой атрибут нетранзитивно зависит от первичного ключа (или от какого-либо ключа, если их несколько).
На практике третья нормальная форма достаточна в большинстве случаев, и приведением к третьей нормальной форме процесс проектирования реляционной базы данных обычно заканчивается. Определения остальных нормальных форм даны, например, в работе [2].
6.4. Построение физической модели БД
Физическая модель БД имеет привязку с конкретной СУБД, выбранной для реализации ИС. Имена атрибутов и типы данных должны соответствовать правилам принятым в выбранной системе.
В большинстве случаев правила именования атрибутов соответствуют синтаксису идентификаторов в языках программирования. Поэтому рекомендуется давать англоязычные имена атрибутам, являющиеся переводом их имен с русского языка.
Заметим, что в физической модели� принята терминология, свойственная языку SQL. В ней сущности соответствует термин �таблица�, а атрибуту - �поле� (таблицы).
Типы данных должны выбираться предельно тщательно и в тесном сотрудничестве с заказчиками ИС. Рекомендуется также произвести анализ данных на основе входных документов с целью четкого определения допустимых диапазонов значений.
7. ПРИМЕР ПРОЕКТИРОВАНИЯ БД
7.1. Предварительное описание предметной области
Предметная область (учебная) – библиотечное хозяйство ВУЗа. Библиотечный фонд состоит только из непериодических изданий (книг). В библиотеке может храниться несколько экземпляров одной и той же книги. По требованию клиентов книги выдаются из книгохранилища. Клиентами библиотеки могут быть как студенты, так и сотрудники ВУЗа. Книги подразделяются на определенные категории (научная литература, общеобразовательная и т.д.).
Необходимо разработать физическую модель БД, которая позволит выполнять ИС следующие функции:
- вести учет выдачи книг;
- вести учет клиентуры библиотеки;
- производить анализ движения книг с целью выявления наиболее популярных категорий, издательств и авторов и прогнозирования спроса на книги.
7.2. Этап 1. Анализ предметной области
Сначала, на основе предварительного описания и, прежде всего, описания информационных потребностей выделим основные сущности предметной области:
1) книга;
2) клиент;
3) категория книг;
4) издательство;
5) автор;
6) экземпляр книги.
Далее, нам необходимо выявить атрибуты этих сущностей. Для этого заказчику должны быть заданы вопросы (анкетирование или интервьюирование), позволяющие определить какие свойства и характеристики данных объектов значимы для него и необходимы для удовлетворения его информационных потребностей. Полученные ответы позволяют нам построить первый вариант модели БД, который можно отобразить ER-диаграммой.
Допустим, что в нашем варианте ответы заказчика привели к диаграмме, представленной на рис. 7.
|
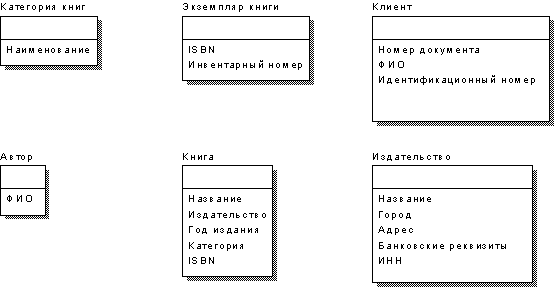
Рис. 7. Первый вариант модели БД.
Теперь совместно с заказчиком необходимо выявить первичные ключи. Лучше всего произвести это в процессе интервьюирования. При этом можно и даже желательно использовать ER-диаграмму. Однако далеко не всегда следует употреблять в беседе с заказчиком такие термины как �сущность�, �атрибут� и �первичный ключ�. Например, для определения первичного ключа сущности КНИГА можно задать такие вопросы: могут две разные книги иметь одинаковое название или могут разные книги иметь один и тот же ISBN? Интервьюирование заказчика на данном этапе должно нам позволить выявить все первичные ключи и построить диаграмму, представленную на рис. 8.
![]()
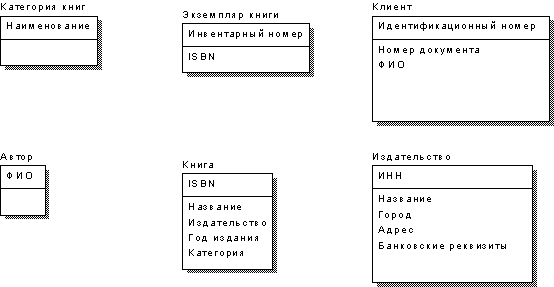
Рис. 8. Модель БД с первичными ключами
Теперь, путем интервьюирования, определим связи между сущностями и их мощность (рис.9). Если модель строится с помощью CASE-средства, то возможно потребуется переименовать некоторые внешние ключи.
|
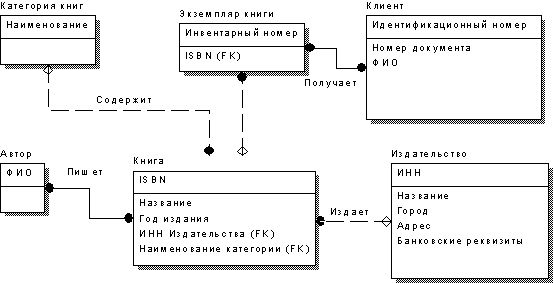
Рис. 9. Модель БД со связями
7.3. Этап 2. Преобразование связей многие-ко-многим
На данном этапе работа хотя и может производиться без участия заказчика, но все же желательно его привлечь для возможного определения дополнительных атрибутов появляющихся при этом сущностей.
Разбиение связей по описанному выше алгоритму должно привести к диаграмме, показанной на рис. 10.
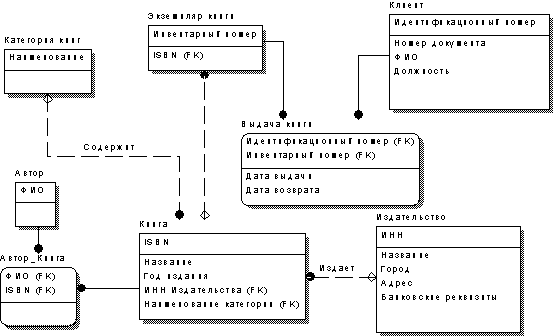
Рис. 10. Модель БД после преобразования связей
Как видно из рисунка, связь между сущностями ЭКЗЕМПЛЯР КНИГИ и КЛИЕНТ была преобразована в сущность ВЫДАЧА КНИГ, в которую по согласованию с заказчиком были добавлены атрибуты ДАТА ВЫДАЧИ и ДАТА ВОЗВРАТА.
7.4. Этап 3. Нормализация БД
Приведем БД к третьей нормальной форме. На этом этапе участие заказчика в работе не требуется. Следует заметить, что при проектировании БД путем построения ER-диаграммы для нормализации, как правило, необходимо произвести минимум преобразований. В нашем случае ненормализованной является сущность КЛИЕНТ. Ее атрибуты ФИО и ДОЛЖНОСТЬ зависят от атрибута НОМЕР ДОКУМЕНТА (удостоверения или студенческого билета). То есть, зная номер документа, можно однозначно определить фамилию и должность клиента. Тем самым сущность КЛИЕНТ не удовлетворяет требованиям 2NF. Для ее нормализации произведем следующие действия:
1. Введем новую сущность ДОКУМЕНТ.
2. Определим в этой сущности первичный ключ НОМЕР ДОКУМЕНТА.
3. Перенесем в нее поля ФИО и ДОЛЖНОСТЬ из сущности КЛИЕНТ.
4. Свяжем сущности ДОКУМЕНТ и КЛИЕНТ связью один-к-одному (сущность ДОКУМЕНТ будет главной).
Результат нормализации представлен на рис. 11.
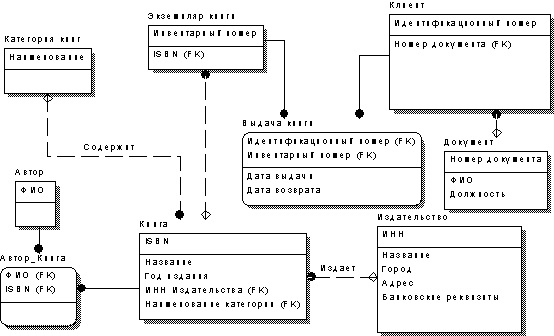
Рис. 11. Модель нормализованной БД
7.5. Этап 4. Построение физической модели БД
Основная задача на этом этапе – правильное определение типов атрибутов. Данная работа должна производиться в тесном сотрудничестве с заказчиком. Кроме того, обязательно необходимо просмотреть примеры входных данных. Ошибка при определении типов атрибутов может привести к серьезным последствиям на этапе эксплуатации системы.
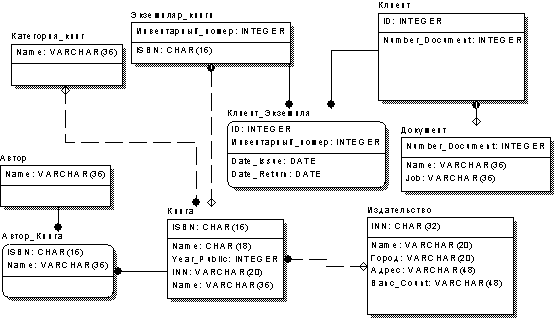
Рис. 12. Физическая модель БД.
Большинство СУБД не требуют определения доменов. В нашем примере желательно определить только один домен – строку с переменной длиной, содержащую символы кириллицы. Причина в том, что для �национальных� строк, как правило, требуется указывать драйвер сортировки символов.
На рис. 12 представлена физическая модель БД для СУБД Interbase 6.0. Подробную информацию о принятых в этой системе типах данных можно почерпнуть из [3].
Из физической модели БД, как уже говорилось выше, может автоматически генерироваться схема базы данных на соответствующей СУБД. На этом проектирование БД заканчивается.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Дайте определения понятиям база данных, модель данных, модель базы данных.
2. Дайте определения понятиям кортеж, отношение, реляционная база данных.
3. Определите понятия атрибут, сущность и связь.
4. Нарисуйте пример ER-диаграммы.
5. Перечислите определения первых трех нормальных форм БД.